First as always i hope everyone is safe oh Dear Readers. Secondly, i am going to write about something that i have been pondering for quite some time, probably close to two decades.
What i call Religion Of Warez (ROWZ).
This involves someone who i hold in the highest regard YOU the esteemed developer.
Marc Andreeson famously said “Software Is Eating The Word”. Here is the original blog:
There is a war going on for your attention. There is a war going on for your thumb typing. There is a war going on for your viewership. There is a war going on for your selfies. There is a war going on for your emoticons. There is a war going on for github pull requests.
There is a war going on for the output of your prompting.
We have entered into The Great Cognitive Artificial Intelligence Arms Race (TGCAIAR) via camps of Large Languge Model foundational model creators.
The ability to deploy the warez needed to wage war on YOU Oh Dear Reader is much more complex from an ideological perspective. i speculate that Software if i may use that term as an entity is a non-theistic religion. Even within the Main Tabernacle of Software (MTOS) there are various fissures of said religions whether it be languages, architectures or processes.
Let us head over to the LazyWebTM and do a cursory search and see what we find[1] concerning some comparison numbers for religions and software languages.
In going to wikipedia we find:
According to some estimates, there are roughly 4,200 religions, churches, denominations, religious bodies, faith groups, tribes, cultures, movements, ultimate concerns, which at some point in the future will be countless.
Wikipedia
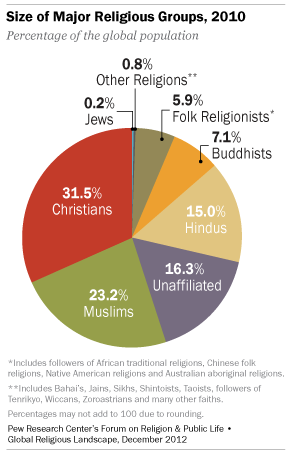
Worldwide, more than eight-in-ten people identify with a religious group. i suppose even though we don’t like to be categorized, we like to be categorized as belonging to a particular sect. Here is a telling graphic:
Let us map this to just computer languages. Just how many computer languages are there? i guessed 6000 in aggregate. There are about 700 main programming languages, including esoteric coding languages. From what i can ascertain some only list notable languages add up to 245 languages. Another list called HOPL, which claims to include every programming language ever to exist, puts the total number of programming languages at 8,945.
So i wasn’t that far off.
Why so much kerfuffle on languages? For those that have ever had a language discussion, did it feel like you were discussing religion? Hmmmm?
Hey, my language does automatic heap management. Why are you messing with memory allocation via this dumb thing called pointers?
The Art of Computer Programming is mapping an idea into a binary computational translation (classical computing rates apply). This process is highly inefficient compared to having binary-to-binary discussions[2]. Note we are not even considering architectures or methods in this mapping. Let us keep it at English to binary representation. What is the dimensionality reduction for that mapping? What is lost in translation?
As i always like to do i refer to Miriam Webster Dictionary. It holds a soft spot in my heart strings as i used to read it in grade school. (Yes i read the dictionary…)
Religion: Noun
re·li·gion (ruh·li·jen)
: a cause, principle, or system of beliefs held to with ardor and faith
Well, now, Dear Reader, the proverbial plot thickens. A System of Beliefs held to faith. Nowadays, religion is utilized as a concept today applied for a genus of social formations that includes several members, a type of which there are many tokens or facets.
If this is, in fact, the case, I will venture to say that Software could be considered a Religion.
One must then ask? Is there “a model” to the madness? Do we go the route of the core religions? Would we dare say the Belief System Of The Warez[3] be included as a prominent religion?
Symbols Of The World Religions
I have said several times and will continue to say that Software is one of the greatest human endeavors of all time. It is at the essence of ideas incarnate.
It has been said that if you adopt the science, you adopt the ideology. Such hatred or fear of science has always been justified in the name of some ideology or other.
If we take this as the undertone for many new aspects of software, we see that the continuum of mind varies within the perception of the universe by which we are affected by said software. It is extremely canonical and first order.
Most often, we anthropomorphize most things and our software is no exception. It is as though it were an entity or even a thing in the most straightforward cases. It is, in fact, neither. It is just information imputed upon our minds via probabilistic models via non convex optimization methods. It is as if it was a Rorschach test that allowed many people to project their own meaning onto it (sound familiar?).
Let me say this a different way. With the advent of ChatGPT we seem to desire IT to be alive or reason somehow someway yet we don’t want it to turn into the terminator.
Stock market predictions – YES
Terminator – NO.
The Thou Shalts Will Kill You
~ Joseph Campbell
Now we are entering a time very quickly where we have “agentic” based large language models that can be scripted for specific tasks and then chained together to perform multiple tasks.
Now we have large language models distilling information gleaned from other LLMs. Who’s peanut butter is in the chocolate? Is there a limit of growth here for information? Asymptotic token computation if you will?
We are nowhere near the end of writing the Religion Of Warez (ROWZ) sacred texts compared to the Bible, Sutras, Vedas, the Upanishads, and the Bhagavad Gita, Quran, Agamas, Torah, Tao Te Ching or Avesta, even the Satanic Bible. My apologies if i left your special tome out it wasn’t on purpose. i could have listed thousands. BTW for reference there is even a religion called the Partridge Family Temple. The cult’s members believe the characters are archetypal gods and goddesses.
In fact we have just begun to author the Religion Of Warez (ROWZ) sacred text. The next chapters are going be accelerated and written via generative adversarial networks, stable fusion and reinforcement learning transformer technologies.
Which, then, one must ask which Diety are YOU going to choose?
i wrote a little stupid python script to show relationships of coding languages based on dates for the main ones. Simple key value stuff. All hail the gods K&R for creating C.
import networkx as nx
import matplotlib.pyplot as plt
def create_language_graph():
G = nx.DiGraph()
# Nodes (Programming languages with their release years)
languages = {
"Fortran": 1957, "Lisp": 1958, "COBOL": 1959, "ALGOL": 1960,
"C": 1972, "Smalltalk": 1972, "Prolog": 1972, "ML": 1973,
"Pascal": 1970, "Scheme": 1975, "Ada": 1980, "C++": 1983,
"Objective-C": 1984, "Perl": 1987, "Haskell": 1990, "Python": 1991,
"Ruby": 1995, "Java": 1995, "JavaScript": 1995, "PHP": 1995,
"C#": 2000, "Scala": 2003, "Go": 2009, "Rust": 2010,
"Common Lisp": 1984
}
# Adding nodes
for lang, year in languages.items():
G.add_node(lang, year=year)
# Directed edges (influences between languages)
edges = [
("Fortran", "C"), ("Lisp", "Scheme"), ("Lisp", "Common Lisp"),
("ALGOL", "Pascal"), ("ALGOL", "C"), ("C", "C++"), ("C", "Objective-C"),
("C", "Go"), ("C", "Rust"), ("Smalltalk", "Objective-C"),
("C++", "Java"), ("C++", "C#"), ("ML", "Haskell"), ("ML", "Scala"),
("Scheme", "JavaScript"), ("Perl", "PHP"), ("Python", "Ruby"),
("Python", "Go"), ("Java", "Scala"), ("Java", "C#"), ("JavaScript", "Rust")
]
# Adding edges
G.add_edges_from(edges)
return G
def visualize_graph(G):
plt.figure(figsize=(12, 8))
pos = nx.spring_layout(G, seed=42)
years = nx.get_node_attributes(G, 'year')
# Color nodes based on their release year
node_colors = [plt.cm.viridis((years[node] - 1950) / 70) for node in G.nodes]
nx.draw(G, pos, with_labels=True, node_color=node_colors, edge_color='gray',
node_size=3000, font_size=10, font_weight='bold', arrows=True)
plt.title("Programming Language Influence Graph")
plt.show()
if __name__ == "__main__":
G = create_language_graph()
visualize_graph(G)
Programming Relationship Diagram
So, folks, let me know what you think. I am considering authoring a much longer paper comparing behaviors, taxonomies and the relationship between religions and software.
i would like to know if you think this would be a worthwhile piece?
Until Then,
#iwishyouwater <- Banzai Pipeline January 2023. Amazing.
@tctjr
MUZAK TO BLOG BY: Baroque Ensemble Of Vienna – “Classical Legends of Baroque”. i truly believe i was born in the wrong century when i listen to this level of music. Candidly J.S. Bach is by far my favorite composer going back to when i was in 3rd grade. BRAVO! Stupdendum Perficientur!
[1] Ever notice that searching is not finding? i prefer finding. Someone needs to trademark “Finding Not Searching” The same vein as catching ain’t fishing.
[2] Great paper from OpenAI on just this subject: two agents having a discussion (via reinforcement learning) : https://openai.com/blog/learning-to-communicate/ (more technical paper click HERE)
[3] For a great read i refer you to the The Ware Tetralogy by Rudy Rucker: Software (1982), Wetware (1988), Freeware (1997), Realware (2000)
[4] When the words “software” and “engineering” were first put together [Naur and Randell 1968] it was not clear exactly what the marriage of the two into the newly minted term really meant. Some people understood that the term would probably come to be defined by what our community did and what the world made of it. Since those days in the late 1960’s a spectrum of research and practice has been collected under the term.
One life on this earth is all that we get, whether it is enough or not enough, and the obvious conclusion would seem to be that at the very least we are fools if we do not live it as fully and bravely and beautifully as we can.
Frederick Buechner
First, as always, i trust everyone is safe. Second, i trust everyone had an amazing holiday with your family and friends hopefully did something “screen-free”. It is the start of a new year.
i am changing gears just a little and writing on a subject that, at first blush, might appear morose, yet it is not. in fact quite the opposite.
What Is Your Eulogy?
Yep i went THERE. (Ever notice that once you arrive, you are there and think about somewhere else?)
If you go to my About page, you will see that I set this site up mainly to be a memory machine for me and a digital reference for My Family and Friends in addition, if along the way, i entertain someone on the WorldWideWait(tm) all the better. A reference for a future memory if you will.
I am taking complete editorial advantage of paying the AWS bill every month, and there is a “.org” at the end of the site name denoting a not-for-profit site supposedly like a religion. i can say what i want, i suppose—well, still within reason nowadays. Free Speech, They Said… Yet, I digress.
I will persist until I succeed.
I was not delivered unto this world in defeat, nor does failure course in my veins. I am not a sheep waiting to be prodded by my shepherd. I am a lion and I refuse to talk, to walk, to sleep with the sheep. I will hear not those who weep and complain, for their disease is contagious. Let them join the sheep. The slaughterhouse of failure is not my destiny.
I will persist until I succeed.
~ OG Mandino
For context, this subject matter was initiated on the conflagration of several disparate events:
i introduced one of my progeny to Mozart’s Requiem in D minor, K. 626, aka Lacrimosa. We discussed the word Requiem, and then she immediately informed me that Lacrimosa means Sorrow in Latin and in the key of D minor. Wow, thank you, i said. (maybe something is sticking…)
An old friend whom I hadn’t seen in years passed away the day after I emailed him I contacted him to discuss some audio subject material that I enjoyed speaking with him about in detail. Alas, another cancer victim.
i took a class put on by Mathew McConaughey and Tony Robbins called “The Art of Living” and the book The Greatest Salesman by OG Madino was featured in class.
Since I started this piece, even more humans who are dear to me have passed or received extremely dire news.
i just wanted to scribe these thoughts in order to “remind me to remember”.
Life Should be One Great Adventure or Nothing.
Helen Keller
So here we go… it is tl;dr fo’ sho’.
In one of the aforementioned classes, the subject matter was the title of this blog. I originally had planned to calll this blog “Do Not Be Awed Into Submission,” where most people nowadays are “awed” by TikTok,Instagram or YouTube videos of people doing stuff and keep themselves from truly creating and DOING stuff in their own lives. They just sit and watch sports, listen to podcasts and “consume” without using that information to create. It seems to me, at least, that most people nowadays spectate instead of create or participate.
Yet i started reflecting on the subject matter as this blog has been in draft form for over a year. Another year passed, another amazing birthday (afaic the most important holiday), and here we are, a New Year into 2025.
So given all that context and background:
What do i want to be known for when Ye Ole #EndOTimes is forthcoming? (Note: for those word freaks out there, it is called Eschatology from Greek (who else?) ἔσχατος (éskhatos).
This is the CENTRAL SCRUTINIZER Joe has just worked himself into an imaginary frenzy during the fade-out of his imaginary song, He begins to feel depressed now. He knows the end is near. He has realized at last that imaginary guitar notes and imaginary vocals exist only in the mind of the imaginer. And ultimately, who gives a f**k anyway? HAHAHAHA!…Excuse me…so who gives a f**k anyway? So he goes back to his ugly little room and quietly dreams his last imaginary guitar solo…
~ Frank Zappa From Watermelon In Easter Hey
i believe at this point, at the end of this thing called life, pretty much for me, are the following attributes that i want to be known for as best as possible i can be:
Maintaining a sheer sense of wonder and awe for Life
If you note, most of these items are items i can control or affect. You say well, what about being a good friend, spouse, parent? Well, to the best of your ability, you can try to be the best at those, but ultimately, someone else is judging YOU. In fact, we are always judged, and in fact, I will say that most people judge – consciously or subconsciously, ergo, Judge as Ye Be Judged.
As well as, and i hope duly noted, some of those items are controversial. Oh Dear Reader, this wont be the first time i have been associated with controversial.
You have enemies? Why, it is the story of every man who has done a great deed or created a new idea. It is the cloud which thunders around everything that shines. Fame must have enemies, as light must have gnats. Do not bother yourself about it; disdain. Keep your mind serene as you keep your life clear.
~ Victor Hugo
To the best of my ability, I will attempt to provide definitions and context for the above attributes. One additional context is that these are couched in “individualistic” references, not societal norms, overlays or programming.
Honor and Integrity
Honor and integrity are ethical concepts that are often intertwined but have distinct meanings:
Honor
Honor refers to high respect and esteem, often tied to one’s actions, character, and adherence to a code of conduct. It is about upholding a personal set of values considered virtuous and deserving of respect and maintaining one’s reputation and dignity through ethical behavior and moral decision-making.
Integrity
Integrity is the quality of being honest and having strong moral principles. It involves consistently adhering to ethical standards and being truthful, fair, and just in all situations. Key aspects of integrity include being truthful and transparent in one’s actions and communications and acting according to one’s values and principles even when it is challenging, inconvenient, or, in many cases, seemingly impossible.
Essentially, it is standing up for “what is right” (as one views in and unto oneself), even within and to the point of adversity or personal loss.
What is good? – All that heightens the feelings of power, the will to power, power itself in man. What is bad? – All that proceeds from weakness. What is happiness? – The feeling that power increases – that a resistance is overcome.
~ Friedrich Nietzsche
Honor and integrity form the foundation of a trustworthy and respected character. Honor emphasizes the external recognition of one’s ethical behavior, while integrity focuses on the internal adherence to moral principles. Your moral compass is extremely individualistic. In full transparency given that i believe there is no original sin some have questioned how in the world can i have such moral character. Literally, someone said to me: “Given how you view things, how do you have such high morals compared to everyone else.” (NOTE: This question came from a very religious, devout, wonderful person i love.).
It is better to be hated for what you are than to be loved for what you are not.
~ Andre Gide
Brutal Honesty
Brutal honesty refers to being extremely direct and unfiltered in communication, often to the point of being blunt or harsh. This form of honesty prioritizes telling the truth without considering the potential impact on the feelings or reactions of others. It sorta kinda exactly goes hand in hand with Integrity which in turn connects to Honor.
Key aspects of brutal honesty include:
Directness: Providing straightforward and unvarnished truth without sugarcoating or softening the message.
Bluntness: Being frank (or Ted) and candid, even if the truth may be uncomfortable or hurtful.
There isn’t a coffee table book entitled “Mediocore Humans In History”
~ C.T.T.
So why try to toe the Brutal Honesty Line?
Clarity: It can eliminate misunderstandings and provide a clear and unambiguous message. Also, it lets people know where you stand.
Trust: Some people appreciate brutal honesty because it demonstrates a commitment to truthfulness and transparency. I’ve had folks come back to me later and thanked me. Which is really rad of them.
Efficiency: It can get to the heart of an issue without dancing around the subject. Once again, note the time savings component. It saves a ton of time. HUUUUUUOOOOOGGGEEE time saver.
Potential Drawbacks
If you are delivering negative information to someone this can have drawbacks. If you are delivering positive news, do it with gusto! However, this situation can occur.
Hurt Feelings: It can cause emotional harm or strain relationships due to the harsh delivery. Deliver honest negative information with proper propriety and courtesy. They will hopefully get over it if they have any self-reflection.
Perception of Rudeness: It may be perceived as insensitive, disrespectful, lack of empathy, or unnecessarily harsh. However, if you are running a company or in a particularly toxic relationship, great results take drastic measures.
Conflict: It can lead to conflicts or defensive reactions from those who receive the message. Some say life is all conflict. Once again don’t go looking for trouble but you cannot shy away from interactions.
The harder the conflict, the more glorious the triumph.
~ Thomas Paine
Caveat Emptor: As implicit in the above commentary, Brutal Honesty should be balanced with surgical and thoughtful empathy and, shall we say, nuance to ensure that the truth is communicated effectively and respectfully. For instance, it is okay to lie and say someone’s baby is cute. In the same fashion, eating everything on your plate when they have asked you over for supper at a neighbor’s house is also good manners, even though you probably do not like well-done pot roast and peas. Say thank you, and it was delicious. In Everything, practice propriety and courtesy.
When you have lived your individual life in YOUR OWN adventurous way and then look back upon its course, you will find that you have lived a model human life, after all.
Professor Joseph Campbell
2. “Living Life Loud” is a phrase that conveys embracing life with enthusiasm, boldness, and authenticity. It suggests living in a way that is vibrant, expressive, and true to oneself. To be authentic and true to yourself, and to embrace your passions and unique perspectives. It can also mean living intentionally and unapologetically, pursuing your dreams with enthusiasm, and stepping outside of your comfort zone.
Here are some aspects of what it means to Live Life Loud:
Authenticity: Being true to yourself and not being afraid to show your true colors, even if they differ from societal norms or expectations.
Boldness: Taking risks, stepping out of your comfort zone, and confidently pursuing your passions and dreams.
Enthusiasm: Approaching life with energy and excitement, making the most out of every moment.
Courage: Facing challenges head-on and standing up for what you believe in, even when it’s difficult.
I wonder, I wonder what you would do if you had the power to dream any dream you wanted to dream?
~ Alan Watts
This seems rather nebulous in some cases, so let us get a little more specific with some examples.
Pursuing Dreams: Actively chasing your goals and aspirations, regardless of how daunting they may seem. Most dreams are impossible; otherwise, they wouldn’t be dreams.
Taking Risks: Being willing to try new things, even if there’s a chance of failure. It goes hand in hand with Pursuing Your Dreams. Someone once said “I need to surf big waves with two oxygen tanks,” i said well you cant surf them then. In the same vein someone told me when discussing my view on creating companies: “I cant take that risk.”, i asked well you drive a car? Trust me that is a much larger risk everyday.”
In the next five seconds what are you going to do to make your life spectacular?
~ Tim O’Reilly
Being Outspoken: Sharing your opinions and ideas confidently, without fear of judgment. Not bragging. Being forthright in your views and taking responsibility for those views. Owning them and being prepared to defend them.
Celebrating Uniqueness: Embracing what makes you different and showcasing it proudly (not loudly). However, not to the point of narcism. Of course, I hear Tyler Durden saying, “You are not a unique snowflake,” whilst also saying, “You are not your f-ing khakis!”
So why live life loud? Well, I’m glad you asked. Here are just some that I wrote down: Being open and expressive can help build deeper, more meaningful relationships. Brutal Honesty with Onesself and the Universe.
This chooses by definition a life of surprise. Living outside the realm of societal norms in most cases.
Potential Challenges
Judgment: Judge So Ye Be Judged! Others may not always understand or accept your loud approach to life, which can lead to criticism or judgment. THEY are going to judge anyway. In fact THEY have judged even before you started living life loud. Why? Because most who judge follow The Herd mentality of Social Norms.
Risk of Failure: Taking bold steps can sometimes lead to setbacks or failures, which require resilience to overcome. However my “hot-take” (isn’t that the lingo?) is once you have stepped out on the edge and attempted to create or do or launch yourself into the air over ice or over the ledge of a heaving wave – YOU WON! Analysis to paralysis is death. Hesitation Kills folks. Remember if you fail you have no where to go but up and if it is a big enough failure you have a great story!
Vulnerability: Being authentic and expressive means being vulnerable, which will be in most cases uncomfortable, I’d rather crawl through glass attempting to obtain My Personal Legend that sit back and think i could have done or what might have been. In fact, most people are frightened more of living the extreme dream than failing. they would rather fail or even said they failed and quit.
All we hear is radio ga ga
Radio goo goo
Radio ga ga
All we hear is radio ga ga
Radio blah, blah
~ Radio GA GA, Queen
Living Life Loud is about making the most of your existence, embracing who you are, and not being afraid to live boldly and authentically. Go to the extreme of that dream, as extreme as you can obtain because, Dear Reader, there are no circumstances, and once you move toward Living Life Loud, there are even as i once believed – no Consequences.
Caveat Emptor: There is no free lunch here at all. The path you choose for your bliss is expensive. The collateral damage is mult-modal. it has been said Humans love a winner but they love a looser more because it makes them feel better about themselves. This also gets into our subconscious programming from society and our families. My Mother not too long ago when i was discussing a subject concerning “taking care of them” and she responded: You go live your life and make no decisions based on others. Others should be so lucky, but they aren’t. The hardest path is YOUR true path. Choose it. Hold It. Protect IT.
Respice post te. Hominem te esse memento. Memento mori.” (“Look after yourself. Remember you’re a man. Remember you will die.”).
~The 2nd-century Christian writer Tertullian reports a general said this during a procession
3. Improving Oneself Daily
Improving oneself mentally, physically, and “spiritually” daily involves a commitment to continuous personal development in both the mind and body. This holistic approach to self-improvement includes activities and habits that promote mental clarity, emotional well-being, and physical health. Here’s a breakdown of what it means:
Mentally
Learning: Engaging in activities that stimulate your mind, such as reading, studying, or learning new skills.
Mindfulness: Practicing mindfulness or meditation to enhance self-awareness, reduce stress, and improve mental clarity.
Positive Thinking: Cultivating a positive mindset by focusing on gratitude, affirmations, and reframing negative thoughts. Stay away from pessimistic people and naysayers.
Problem-Solving: Challenging yourself with puzzles, games, or new experiences that require critical thinking and creativity. Study the subject of neo-plasticity. Brush your teeth with the opposite hand for a week. Drive a new path without Apple/Google/Waze Maps. Or do what i like to do Freedive. Click and read.
Emotional Health: Managing emotions effectively through journaling, therapy, or talking to trusted friends or family members. Take martial arts for defense and emotional health. Punch a bag. Lift heavy weights. Love animals.
Reading: Read, Read and Read More. Not trash novels but deep nonfiction and fiction. Write, take notes when you read.
Physically
Exercise: Engaging in regular physical activity, whether it’s strength training, cardio, yoga, or any other form of exercise that keeps your body active and strong. Get up and MOVE!
Nutrition: Eating a balanced and nutritious diet that fuels your body and supports overall health. i happen to trend towards canivore. It’s difficult, but it changed my life. Again, eating meat lifts heavy things.
Sleep: Ensuring you get adequate and quality sleep to allow your body and mind to recover and function optimally. i can sleep standing up in an airport. Learn how to take power naps.
Daily Habits
Consistency: Make these activities a part of your daily routine to ensure continuous improvement. Discipline above all. Not grit or determination but Discipline. Have a morning routine. Or any routine then allows you the mental freedom to go to other places mentally and physically. Takes cognitive load off you and reduces friction. Eat the same things, dress the same way.
Goal Setting: Setting small, achievable goals that contribute to your long-term personal development. Make your bed everyday. Set goals in the am then reflect in pm. How could you do better tomorrow? Take time each day to reflect on your progress, identify areas for improvement, and celebrate your achievements.
Adaptability: Being open to change and willing to adjust your habits and routines as you learn what works best for you. Try things you wouldn’t normally do – listen to smooth jazz. Try Hot Yoga. Do stuff then you can optimize to your liking. You might try it and like it.
Improving oneself mentally and physically daily is a lifelong commitment to becoming the best version of yourself. It involves dedication, consistency, and a willingness to learn and adapt continually. It is all based on discipline. Full stop. Not motivation, not grit not anything but getting up and MOVING. Go do the thing that scares. you the most or the thing that you deplore the most – D I S C I P L I NE. i lift every day and read something every day.
Without contrairies there no progression. Attraction and replusion, reason and energy, love and hate are necessary for human existence.
~ William Blake
4. Loving (and Hating)
The idea of experiencing both love and hate at their fullest potential emphasizes the importance of embracing the full spectrum of human emotions to lead a richer, more authentic life.
Emotional Authenticity
Full Range of Experience: Experiencing the full range of emotions allows for a deeper understanding of oneself and others. It means accepting and acknowledging all feelings rather than suppressing them. i call this the dynamic range of life. Western society suppresses everything except sadness. it is ok to be sad. Be enraged. Be Full Of Lust and Desire. Know were your limits are if there are any and learn to regulate them as needed.
Self-Awareness: Fully engaging with both love and hate can lead to greater self-awareness and insight into what matters to you and why. If i have been guilty of something is not being aware enough. If there is original sin afaic it is stupidity and non-awareness. Funny how they go hand in hand and do related to loving and hating.
Learning Opportunities: Intense emotions, whether positive or negative, can be powerful teachers. They provide opportunities to learn about your triggers, strengths, weaknesses, and values. Putting yourself out there past the pale teaches you quickly and well. Strong emotions can inspire creativity, leading to profound art, writing, music, and other forms of expression.
Resilience: Navigating through both love and hate can build emotional resilience, helping you manage future challenges more effectively. Experiencing hate or intense dislike can make you appreciate love and positive emotions more deeply, providing a balanced perspective on life. Salt and Pepper anyone?
Remember when you were young, you shown like the Sun. Shine On you Crazy Diamond!
~ Pink Floyd “Shine On You Crazy Diamond”
Loving and Hating will lead to Authentic Relationships.
Deeper Connections: Loving deeply fosters strong, meaningful relationships. Being open about negative emotions can also lead to more honest and authentic interactions. Strong emotions can inspire creativity, leading to profound art, writing, music, and other forms of expression. Confronting and understanding negative emotions can lead to healthier conflict resolution and stronger relationships in the long term.
Caveats and Considerationswhen Loving and Hating
Caveat Emptor: It’s important to express both love and hate in healthy, constructive ways. While deep emotions are natural, how you act on them matters significantly. Ensure that the expression of intense emotions does not harm yourself or others. Finding healthy outlets for negative emotions is crucial. While experiencing emotions entirely is valuable, maintaining a balance is important. Overwhelming negativity or unchecked hatred can be destructive, so it’s essential to seek ways to manage and balance these emotions. Also sometimes we must practice complete indifference. Embracing both love and hate fully can lead to a richer, more nuanced understanding of life, fostering personal growth, deeper relationships, and a more authentic existence.
And the Germans killed the Jews And the Jews killed the Arabs And Arabs killed the hostages And that is the news And is it any wonder That the monkey’s confused
~ Perfect Sense Part 1, Roger Waters
5. Quality Over Quantity
The phrase “quality over quantity” as a human value emphasizes prioritizing the excellence, depth, or meaningfulness of something over merely having more of it. It’s a mindset that values richness, purpose, and intentionality over excess or superficial accumulation. i have a saying: “Best Fewest.” You get the best humans that know how to do something together they can create anything.
Relationships: Valuing meaningful, deep connections with a few people rather than having a large network of acquaintances. Iihave a very small network i can count on one hand, i completely trust. Once you get over 30 you find out who really cares about you. See the quote at the end of the blog. Really those who matter just want you truly happy.
Work: Focusing on producing exceptional work or projects instead of completing many tasks without significant impact or value. That 9 am standup is it really needed? Cant we automate this excel spreadsheet? Think much? Work yourself out of a job and into your passion.
Material Possessions: Preferring fewer high-quality, durable items rather than many cheap, disposable ones. But a high quality custom suit or dress – three of them. Prada, Sene etc. Black, navy, or dark blue with custom shirts. i happen to prefer fench cuffs with cuff links. They never go out of style and will last forever.
There are many who would take my time, I shun them. There are some who share my time, I am entertained by them. There are precious few who contribute to my time, I cherish them.
~ A.S.L.
Time Management: Spending your time on activities that matter and bring fulfillment rather than filling your schedule with things that feel busy but are unimportant or things that people put on you. The above quote is my favorite quote in my life, and if i do have a tombstone, i want it on it. EMBLAZONED!
Essentially, it’s a principle that asks, “What truly matters?” and reminds us to focus on what brings genuine value and satisfaction rather than chasing quantity for the sake of just having more of something.
6. Maintaining a sheer sense of wonder and awe for life
Maintaining a sheer sense of wonder and awe for life means approaching the world with curiosity, gratitude, and an openness to its beauty and mysteries. BE AMAZED AT THE THRALL OF IT ALL! It’s about deeply appreciating the small and large marvels around you—whether it’s the intricacies of nature, the complexities of human connections, or the endless potential for discovery and growth. YOU ARE READING <THIS>. Check out my blog Look Up and Down and All Around – has some cool pictures as well.
It involves letting go of jadedness or routine and instead choosing to see the extraordinary in the ordinary. This mindset keeps you engaged, inspired, and connected to the richness of life, no matter the circumstances. It’s like seeing the world through the eyes of a child, where everything holds the potential for fascination and joy. Turn up the back channel like when you were a child. Be Aware! Be Amazed! Wonder what it is like to be a tree or a rock!
i can say unequivocally that while i have many more mistakes than “performing tasks in a correct fashion” that i have lived a loud and truly individuated life. Would i do things differently? Sure some. I probably would have “sent” it even harder, and past eleven pretty much on everything. i can truly say that i left everything out in the ocean, nothing in the bag and gave it my all. Remember: Take care of those you call your own and keep good company:, storms never last and the forecast calls for Blue Skies!
Enough for now.
For those that truly know me, you know, and I cherish you. 🤘🏻💜.
#iwishyouwater <- if i could do it again, i would live this life. He got the memo.
Music To Blog By: All Of the versions of “Watermelon in Easter Hay”, full name “Playing a Guitar Solo With This Band is Like Trying To Grow a Watermelon in Easter Hay, by Frank Zappa (covers etc) i could find and just loop them. There is even a blue grass version. In their review of the album, Down Beat magazine criticized the song (i despise critics), but subsequent reviewers championed it as Zappa’s masterpiece. Kelly Fisher Lowe called it the “crowning achievement of the album” and “one of the most gorgeous pieces of music ever produced.” I must agree. Supposedly, Zappa told Neil Slaven that he thought it was “the best song on the album. “Watermelon in Easter Hay” is in 9/4 time. The song’s hypnotic arpeggiated pattern is played throughout the song’s nine minutes. The 9/4 time signature keeps the song’s two-chord harmonic structure which until you really listen you don’t realize its a two chord structure. For me i think it is one of the most sonically amazing pieces of music ever written and produced. Sonically, the reverb is amazing. Sonically, the maribas are astounding. Sonically the orchestral percussion is mesmerizing. The song after Watermelon on Joe’s Garage is completely hilarious, “Little Green Rosetta,”and I am putting that on the going away party playlist, and I hope people dance in a conga or kick line and sing it. The grass bone to the ankle bone (listen to the song…).
Think about it a very mediocre guy imagining how he could play, if he could play anything that he wanted to play? Get the reference to the entire blog? Ala Alan Watts, if you could dream any dream, you want to dream? Then what?
The song is, in effect, a dream of freedom.
Here are some other details about “Watermelon in Easter Hay”:
The song’s two alternating harmonies are A and B / E, linked by a G#.
The song is introduced by Zappa as the Central Scrutinizer, which then gives way to a guitar solo.
The song’s snare accents have a lot of reverb and delay, creating a swooosh sound that sometimes sounds like wind.
The song’s guitar solo is the only guitar solo specifically recorded for the album. All others are from a technique known as xenochronous.
Rumor has it Dweezil Zappa is the only person allowed to play it.
Someone called the song intoxicating in one of my other blogs on the Zappa Documentary. Kind of like a really good baklava.
And a couple more items for your thoughts:
Its so hard to forget pain but its even harder to remember hapiness. We have no scar to show for hapiness. We learn so little from peace.
~ Chuck Palahnuik (author of fight club, choke etc)
Those who mind don’t matter and those who matter don’t mind.
~ Dr. Suess
i listen to this every morning. Rest In Power Maestro with the amazing Susanna Rigacci:
~ Professor Benard Widrow (inventor of the LMS algorithm)
Hello Folks! As always, i hope everyone is safe. i also hope everyone had a wonderful holiday break with food, family, and friends.
The first SnakeByte of the new year involves a subject near and dear to my heart: Optimization.
The quote above was from a class in adaptive signal processing that i took at Stanford from Professor Benard Widrow where he talked about how almost everything is a gradient type of optimization and “In Life We Are Always Optimizing.”. Incredibly profound if One ponders the underlying meaning thereof.
So why optimization?
Well glad you asked Dear Reader. There are essentially two large buckets of optimization: Convex and Non Convex optimization.
Convex optimization is an optimization problem has a single optimal solution that is also the global optimal solution. Convex optimization problems are efficient and can be solved for huge issues. Examples of convex optimization include maximizing stock market portfolio returns, estimating machine learning model parameters, and minimizing power consumption in electronic circuits.
Non-convex optimization is an optimization problem can have multiple locally optimal points, and it can be challenging to determine if the problem has no solution or if the solution is global. Non-convex optimization problems can be more difficult to deal with than convex problems and can take a long time to solve. Optimization algorithms like gradient descent with random initialization and annealing can help find reasonable solutions for non-convex optimization problems.
You can determine if a function is convex by taking its second derivative. If the second derivative is greater than or equal to zero for all values of x in an interval, then the function is convex. Ah calculus 101 to the rescue.
Caveat Emptor, these are very broad mathematically defined brush strokes.
So why do you care?
Once again, Oh Dear Reader, glad you asked.
Non-convex optimization is fundamentally linked to how neural networks work, particularly in the training process, where the network learns from data by minimizing a loss function. Here’s how non-convex optimization connects to neural networks:
A loss function is a global function for convex optimization. A “loss landscape” in a neural network refers to representation across the entire parameter space or landscape, essentially depicting how the loss value changes as the network’s weights are adjusted, creating a multidimensional surface where low points represent areas with minimal loss and high points represent areas with high loss; it allows researchers to analyze the geometry of the loss function to understand the training process and potential challenges like local minima. To note the weights can be millions, billions or trillions. It’s the basis for the cognitive AI arms race, if you will.
The loss function in neural networks, measures the difference between predicted and true outputs, is often a highly complex, non-convex function. This is due to:
The multi-layered structure of neural networks, where each layer introduces non-linear transformations and the high dimensionality of the parameter space, as networks can have millions, billions or trillions of parameters (weights and biases vectors).
As a result, the optimization process involves navigating a rugged loss landscape with multiple local minima, saddle points, and plateaus.
Optimization Algorithms in Non-Convex Settings
Training a neural network involves finding a set of parameters that minimize the loss function. This is typically done using optimization algorithms like gradient descent and its variants. While these algorithms are not guaranteed to find the global minimum in a non-convex landscape, they aim to reach a point where the loss is sufficiently low for practical purposes.
This leads to the latest SnakeBtye[18]. The process of optimizing these parameters is often called hyperparameter optimization. Also, relative to this process, designing things like aircraft wings, warehouses, and the like is called Multi-Objective Optimization, where you have multiple optimization points.
As always, there are test cases. In this case, you can test your optimization algorithm on a function called The Himmelblau’s function. The Himmelblau Function was introduced by David Himmelblau in 1972 and is a mathematical benchmark function used to test the performance and robustness of optimization algorithms. It is defined as:
Using Wolfram Mathematica to visualize this function (as i didn’t know what it looked like…) relative to solving for :
Wolfram Plot Of The Himmelblau Function
This function is particularly significant in optimization and machine learning due to its unique landscape, which includes four global minima located at distinct points. These minima create a challenging environment for optimization algorithms, especially when dealing with non-linear, non-convex search spaces. Get the connection to large-scale neural networks? (aka Deep Learnin…)
The Himmelblau’s function is continuous and differentiable, making it suitable for gradient-based methods while still being complex enough to test heuristic approaches like genetic algorithms, particle swarm optimization, and simulated annealing. The function’s four minima demand algorithms to effectively explore and exploit the gradient search space, ensuring that solutions are not prematurely trapped in local optima.
Researchers use it to evaluate how well an algorithm navigates a multi-modal surface, balancing exploration (global search) with exploitation (local refinement). Its widespread adoption has made it a standard in algorithm development and performance assessment.
Several types of libraries exist to perform Multi-Objective or Parameter Optimization. This blog concerns one that is extremely flexible, called OpenMDAO.
What Does OpenMDAO Accomplish, and Why Is It Important?
OpenMDAO (Open-source Multidisciplinary Design Analysis and Optimization) is an open-source framework developed by NASA to facilitate multidisciplinary design, analysis, and optimization (MDAO). It provides tools for integrating various disciplines into a cohesive computational framework, enabling the design and optimization of complex engineering systems.
Key Features of OpenMDAO Integration:
OpenMDAO allows engineers and researchers to couple different models into a unified computational graph, such as aerodynamics, structures, propulsion, thermal systems, and hyperparameter machine learning. This integration is crucial for studying interactions and trade-offs between disciplines.
Automatic Differentiation:
A standout feature of OpenMDAO is its support for automatic differentiation, which provides accurate gradients for optimization. These gradients are essential for efficient gradient-based optimization techniques, particularly in high-dimensional design spaces. Ah that calculus 101 stuff again.
It supports various optimization methods, including gradient-based and heuristic approaches, allowing it to handle linear and non-linear problems effectively.
By making advanced optimization techniques accessible, OpenMDAO facilitates cutting-edge research in system design and pushes the boundaries of what is achievable in engineering.
Lo and Behold! OpenMDAO itself is a Python library! It is written in Python and designed for use within the Python programming environment. This allows users to leverage Python’s extensive ecosystem of libraries while building and solving multidisciplinary optimization problems.
So i had the idea to use and test OpenMDAO on The Himmelblau function. You might as well test an industry-standard library on an industry-standard function!
First things first, pip install or anaconda:
>> pip install 'openmdao[all]'
Next, being We are going to be plotting stuff within JupyterLab i always forget to enable it with the majik command:
## main code
%matplotlib inline
Ok lets get to the good stuff the code.
# add your imports here:
import numpy as np
import matplotlib.pyplot as plt
from openmdao.api import Problem, IndepVarComp, ExecComp, ScipyOptimizeDriver
# NOTE: the scipy import
# Define the OpenMDAO optimization problem - almost like self.self
prob = Problem()
# Add independent variables x and y and make a guess of X and Y:
indeps = prob.model.add_subsystem('indeps', IndepVarComp(), promotes_outputs=['*'])
indeps.add_output('x', val=0.0) # Initial guess for x
indeps.add_output('y', val=0.0) # Initial guess for y
# Add the Himmelblau objective function. See the equation from the Wolfram Plot?
prob.model.add_subsystem('obj_comp', ExecComp('f = (x**2 + y - 11)**2 + (x + y**2 - 7)**2'), promotes_inputs=['x', 'y'], promotes_outputs=['f'])
# Specify the optimization driver and eplison error bounbs. ScipyOptimizeDriver wraps the optimizers in *scipy.optimize.minimize*. In this example, we use the SLSQP optimizer to find the minimum of the "Paraboloid" type optimization:
prob.driver = ScipyOptimizeDriver()
prob.driver.options['optimizer'] = 'SLSQP'
prob.driver.options['tol'] = 1e-6
# Set design variables and bounds
prob.model.add_design_var('x', lower=-10, upper=10)
prob.model.add_design_var('y', lower=-10, upper=10)
# Add the objective function Himmelblau via promotes.output['f']:
prob.model.add_objective('f')
# Setup and run the problem and cross your fingers:
prob.setup()
prob.run_driver()
So this optimized the minima of the function relative to the bounds of and and .
Now, lets look at the cool eye candy in several ways:
# Retrieve the optimized values
x_opt = prob['x']
y_opt = prob['y']
f_opt = prob['f']
print(f"Optimal x: {x_opt}")
print(f"Optimal y: {y_opt}")
print(f"Optimal f(x, y): {f_opt}")
# Plot the function and optimal point
x = np.linspace(-6, 6, 400)
y = np.linspace(-6, 6, 400)
X, Y = np.meshgrid(x, y)
Z = (X**2 + Y - 11)**2 + (X + Y**2 - 7)**2
plt.figure(figsize=(8, 6))
contour = plt.contour(X, Y, Z, levels=50, cmap='viridis')
plt.clabel(contour, inline=True, fontsize=8)
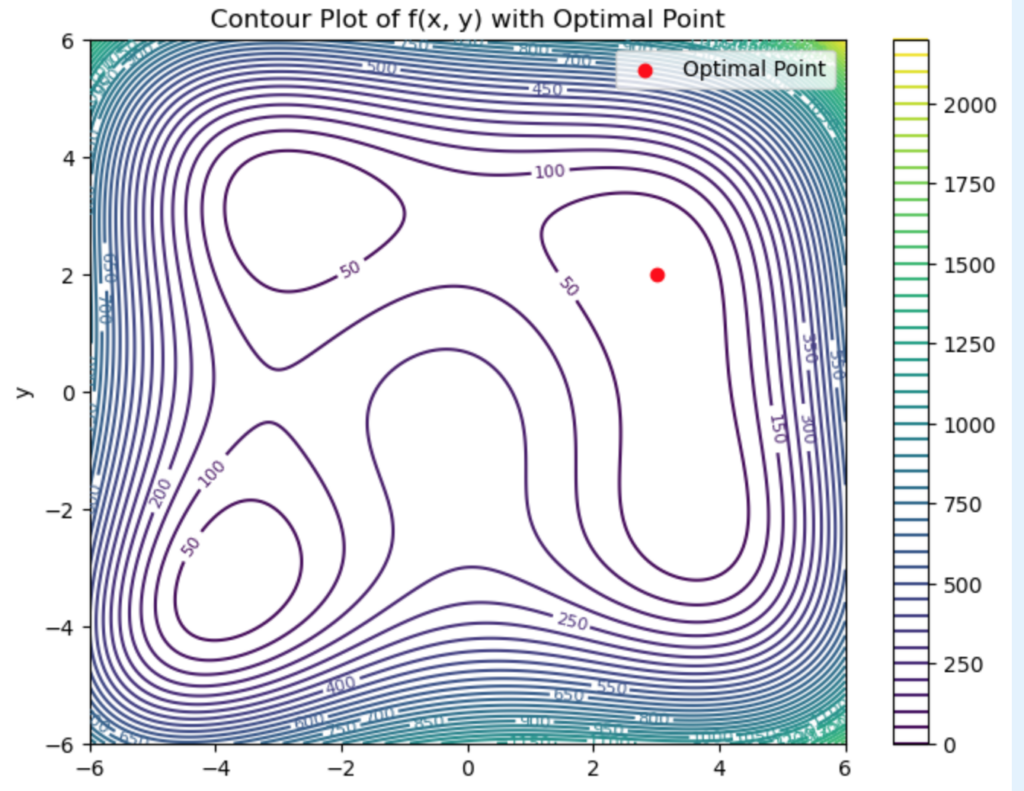
plt.scatter(x_opt, y_opt, color='red', label='Optimal Point')
plt.title("Contour Plot of f(x, y) with Optimal Point")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.colorbar(contour)
plt.show()
Now, lets try something that looks a little more exciting:
import numpy as np
import matplotlib.pyplot as plt
# Define the function
def f(x, y):
return (x**2 + y - 11)**2 + (x + y**2 - 7)**2
# Generate a grid of x and y values
x = np.linspace(-6, 6, 500)
y = np.linspace(-6, 6, 500)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# Plot the function
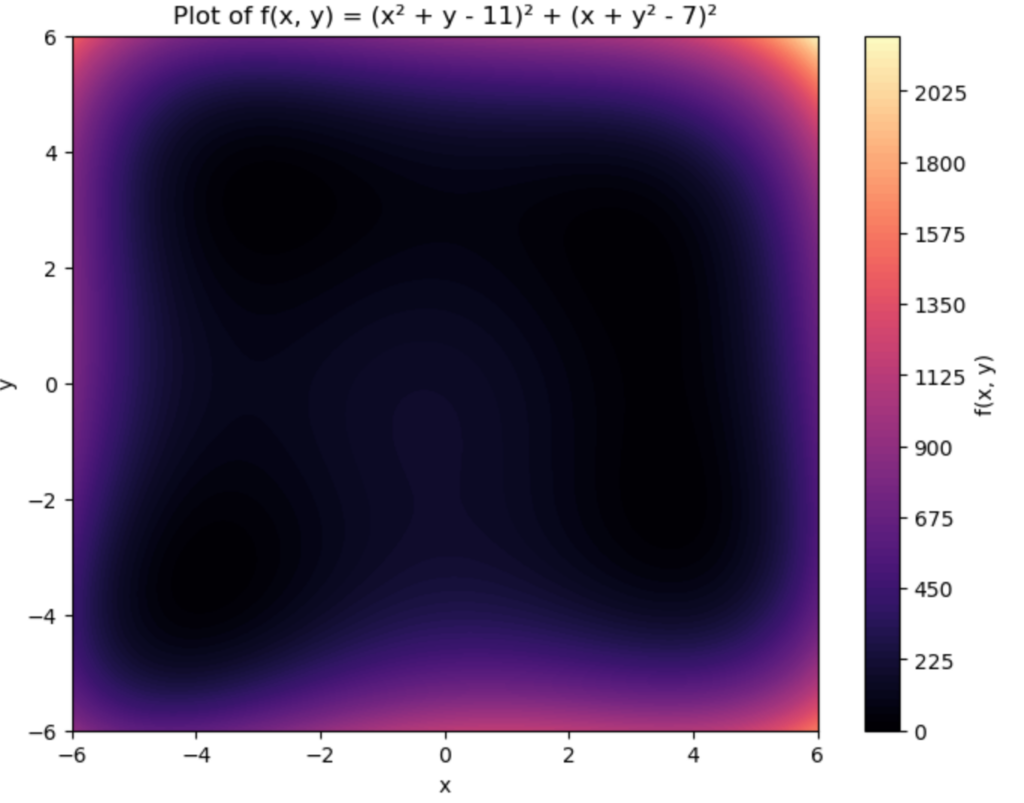
plt.figure(figsize=(8, 6))
plt.contourf(X, Y, Z, levels=100, cmap='magma') # Gradient color
plt.colorbar(label='f(x, y)')
plt.title("Plot of f(x, y) = (x² + y - 11)² + (x + y² - 7)²")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
That is cool looking.
Ok, lets take this even further:
We can compare it to the Wolfram Function 3D plot:
from mpl_toolkits.mplot3d import Axes3D
# Create a 3D plot
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
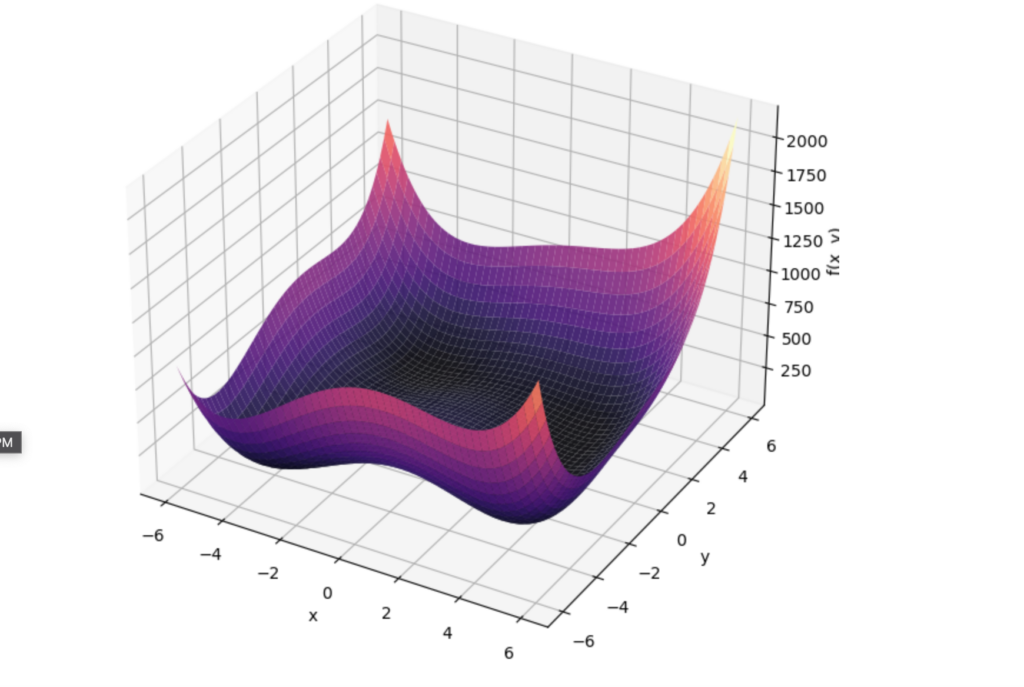
# Plot the surface
ax.plot_surface(X, Y, Z, cmap='magma', edgecolor='none', alpha=0.9)
# Labels and title
ax.set_title("3D Plot of f(x, y) = (x² + y - 11)² + (x + y² - 7)²")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("f(x, y)")
plt.show()
Which gives you a 3D plot of the function:
3D Plot of f(x, y) = (x² + y – 11)² + (x + y² – 7)²
While this was a toy example for OpenMDAO, it is also a critical tool for advancing multidisciplinary optimization in engineering. Its robust capabilities, open-source nature, and focus on efficient computation of derivatives make it invaluable for researchers and practitioners seeking to tackle the complexities of modern system design.
i hope you find it useful.
Until Then,
#iwishyouwater <- The EDDIE – the most famous big wave contest ran this year. i saw it on the beach in 2004 and got washed across e rivermouth on a 60ft clean up set that washed out the river.






![\[f(x, y) = (x^2 + y - 11)^2 + (x + y^2 - 7)^2\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-23ec65f33d158fdb3b13461e54d04f1a_l3.png "Rendered by QuickLaTeX.com")
 :
:
 and
and  and
and  .
.