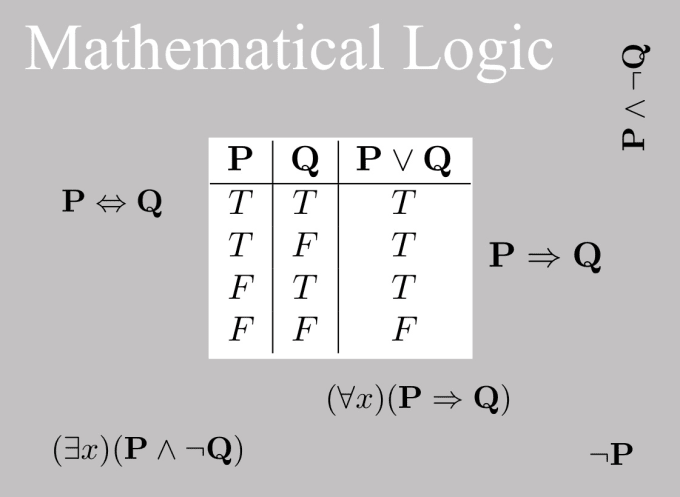Pre-Computing War
Sora’s idea of a Neon Drone War With Audio Track
Sometimes it is the people no one can imagine anything of who do the things no one can imagine.
~ Alan Turing
First, i trust everyone is safe. Second, i had a creative spurt of late and wrote the following blog in one sitting after waking up thinking about the subject.
NOTE: This post is in no way indicative of any stance or provides any classified information whatsoever. It is only a thought piece concerning current technology-driven areas of concern.
Preamble
There is a paradigm shift happening that will affect future generations and possibly the very essence of what it means to be human, and this comes from how technology is transforming war. We stand at a precipice, gazing into a future where the tools of war no longer resemble the clashing steel and human courage of centuries past. How important is conflict to humanity? What is the essence and desire for this conflict? The current uptick in drone usage of the past years has created an inflection point for what I am terming “abstraction levels for engagement.”
We continue to underestimate how important drones are going to be in warfare—a miscalculation that echoes through history’s long ledger of missed signals. I’m going to go out on a long limb here and say the future of most warfare will be enabled by, driven by, and spearheaded by drones. In fact, other than some other types of autonomous vehicles, there might not be anything else on the battlefield.
Here is a definition (of course, AI bot generated because really who reads Webster’s Dictionary nowadays? For the record, i have read Webster’s 3 times front to back):
“A military drone, also known as an unmanned aerial vehicle (UAV) or unmanned aircraft system (UAS), is an aircraft flown without a human pilot on board, controlled remotely or autonomously, and used for military missions like surveillance, reconnaissance, and potentially combat operations. “
This isn’t hyperbole; it’s the logical endpoint of a trajectory we’ve been on since the first unmanned systems took flight. And at the end of that trajectory lies something even more radical: autonomous bullets—not merely guided, but self-directed, a fusion of machine intelligence and lethal intent that could redefine conflict itself.
Note: I edited this part as the kind folk on The LazyWeb(tm) were laser-focused on the how of “smart bullets.: Great feedback and thank you. git push -u -f origin main.
Guided autonomous bullets, often referred to as “smart bullets,” represent an advanced leap in projectile technology, blending precision guidance systems with small-caliber ammunition. These bullets are designed to adjust their flight path mid-air to hit a target with exceptional accuracy, even if the target is moving or environmental factors like wind interfere. The concept builds on precision guided munitions used in larger systems like missiles, but shrinks the technology to fit within the constraints of a bullet fired from a firearm.
Autonomous bullets, often referred to as “smart bullets,” are advanced projectiles designed to adjust their trajectory mid-flight to hit a target with high precision, even under challenging conditions like wind or a moving target. While the concept might sound like science fiction, significant research has been conducted, particularly by organizations like DARPA (Defense Advanced Research Projects Agency) and Sandia National Laboratories, to make this technology a reality.
The core idea behind autonomous bullets is to integrate guidance systems into small-caliber projectiles, allowing them to self-correct their path after being fired. One of the earliest designs, as described in “historical research”, involved a bullet with three fiber-optic sensors (or “eyes”) positioned around its circumference to provide three-dimensional awareness. A laser is used to designate the target, and as the bullet travels, these sensors detect the laser’s light. The bullet adjusts its flight path in real time to ensure an equal amount of laser light enters each sensor, effectively steering itself toward the laser-illuminated target. This method prevents the bullet from making drastic turns like a missile. Still, it enables small, precise adjustments to hit exactly where the laser is pointed, even if the target is beyond visual range or the laser source is separate from the shooter. It hath been said that if you can think it DARPA has probably built it, maybe.
Given the advancements in drones, unmanned autonomous vehicles, land and air vehicles, and supposedly smart bullets (only the dark web knows how they work), imagine a battlefield stripped of human presence, not out of cowardice but necessity. The skies a deafening hum with swarms of drones (if a drone makes a sound and no one is there to hear it, does it make a sound?), each a “node” orchestrated via particle swarm AI models in a vast, decentralized network of artificial minds.
No generals barking orders, no soldiers trudging through mud, just silicon and steel executing a dance of destruction with precision beyond human capacity. The end state of drones isn’t just remote control or pre-programmed strikes; it’s autonomy so complete that the machines themselves decide who lives and who dies – no human in the loop. Self-directed projectiles, bullets with brains roaming the theater of war, seeking targets based on algorithms fed by real-time data streams. The vision feels like science fiction, yet the pieces already fall into place.
Generals gathered in their masses
just like witches at black masses
evil minds that plot destruction
sorcerers of death’s construction
in the fields the bodies burning
as the war machine keeps turning
death and hatred to mankind
poisoning their brainwashed minds, oh lord yeah!~ War Pigs, Black Sabbath 1970
This shift isn’t merely tactical; it’s existential. Warfare has always been a contest of wills, a brutal arithmetic of resources and resolve. But what happens when we can compute the outcome before the first shot is fired? Drones, paired with advanced AI, offer the tantalizing possibility of simulating conflicts down to the last variable terrain, weather, enemy morale, and supply lines, all processed in milliseconds by systems that learn as they go. The autonomous bullet isn’t just a weapon; it’s a data point in a larger Markovian equation, one that could predict victory or defeat with chilling accuracy.
We’re not far from a world where wars are fought first in the cloud, their outcomes modeled and refined, before a single drone lifts off.If the future of warfare is of drone swarms of autonomous systems culminating in self-directed bullets, then pre-computing its outcomes becomes not just feasible but imperative. The battlefield of tomorrow isn’t a chaotic melee; it’s a high-stakes game, a multidimensional orchestrated chessboard where game theory, geopolitics, and macroeconomics converge to predict the endgame before the first move. To compute warfare in this way requires us to distill its essence into variables, probabilities, and incentives a task as daunting as it is inevitable. Yet again, there exists a terminology for this orchestrated chess game. Autonomous asymmetric mosaic warfighting, a concept explored by DARPA, envisions turning complexity into an asymmetric advantage by using networked, smaller, and less complex systems to overwhelm an adversary with a multitude of capabilitiesnvisions turning complexity into an asymmetric advantage by using networked, smaller, and less complex systems to overwhelm an adversary with a multitude of capabilities.
“A Nash equilibrium is a set of strategies that players act out, with the property that no player benefits from changing their strategy. ~ Dr John Nash.”
Computational Game Theory: The Logic of Lethality
At its core, warfare is a strategic interaction, a contest where players, nations, factions, or even rogue actors vie for dominance under the constraints of resources and information. Game theory offers the scaffolding to model this. Imagine a scenario where drones dominate: each side deploys autonomous swarms, programmed with decision trees that weigh attack, retreat, or feint based on real-time data. The payoff matrix isn’t just about territory or casualties, it’s about disruption, deterrence, and psychological impact. A swarm’s choice to strike a supply line rather than a command center could shift an enemy’s strategy, forcing a cascade of recalculations.
Now, introduce autonomous bullets, self-directed agents within the swarm. Each bullet becomes a player in a sub-game, optimizing its path to maximize damage while minimizing exposure. The challenge lies in anticipating the opponent’s moves: if both sides rely on AI-driven systems, the game becomes a duel of algorithms, each trying to out-predict the other. Zero-sum models give way to dynamic equilibria, where outcomes hinge on how well each side’s AI can bluff, adapt, or exploit flaws in the other’s logic. Pre-computing this requires vast datasets, historical conflicts, behavioral patterns, and even cultural tendencies fed into simulations that run millions of iterations, spitting out probabilities of victory, stalemate, or collapse.
Geopolitics: The Board Beyond the Battlefield
Warfare doesn’t exist in a vacuum; the shifting tectonic plates of geopolitics shape it. To pre-compute outcomes, we must map the global chessboard—alliances, rivalries, and spheres of influence. Drones level the playing field, but their deployment reflects deeper asymmetries. A superpower with advanced AI and manufacturing might flood the skies with swarms, while a smaller state leans on guerrilla tactics, using cheap, hacked drones to harass and destabilize. The game-theoretic model expands: players aren’t just combatants but also suppliers, proxies, and neutral powers with their own agendas.
Take energy as a (the main) variable: drones require batteries, rare earths, and infrastructure. A nation controlling lithium mines or chip fabs holds leverage, tipping the simulation’s odds. Sanctions, trade routes, and cyber vulnerabilities—like a rival hacking your drone fleet’s firmware—become inputs in the equation. Geopolitical stability itself becomes a factor: if a war’s outcome hinges on a fragile ally, the model must account for the likelihood of defection or collapse. Pre-computing warfare here means forecasting not just the battle, but the ripple effects—will a decisive drone strike trigger a refugee crisis, a shift in NATO’s posture, or a scramble for Arctic resources? The algorithm must think in networks, not lines.
I visualize a time when we will be to robots what dogs are to humans, and I’m rooting for the machines.
~ Claude Shannon
Macroeconomics: The Sinews of Silicon War
No war is won without money, and drones don’t change that; they just rewrite the budget. Pre-computing conflict demands a macroeconomic lens: how much does it cost to field a swarm versus defend against one? The economics of autonomous warfare favor scale mass-produced drones and bullets could outpace legacy systems like jets or tanks in cost-efficiency. A simulation might pit a 10 billion dollar defense budget against a 1 billion dollar insurgent force, factoring in production rates, maintenance, and the price of countermeasures like EMPs or jamming tech.
But it’s not just about direct costs. Markets react to war’s shadow oil spikes, currencies wobble, tech stocks soar or crash based on who controls the drone supply chain (it is all about that theta/beta folks). A protracted conflict could drain a nation’s reserves, while a swift, computed victory might bolster its credit rating. The model must integrate these feedback loops: if a drone war craters a rival’s economy, their ability to replenish dwindles, tilting the odds. And what of the peacetime economy? States that mastering autonomous tech could dominate postwar reconstruction, turning military R&D into a geopolitical multiplier. Pre-computing this requires economic forecasts layered atop the game-theoretic core—GDP growth, inflation, and consumer confidence as resilience proxies.
The Supreme Lord said: I am mighty Time, the source of destruction that comes forth to annihilate the worlds. Even without your participation, the warriors arrayed in the opposing army shall cease to exist.~ Bhagavad Gita 11:32
The Synthesis: Simulating the Unthinkable
To tie it all together, picture a supercomputer or a distributed AI network running a grand simulation. It ingests game-theoretic strategies (strike patterns, bluffing probabilities), geopolitical alignments (alliances, resource choke points), and macroeconomic trends (war budgets, trade disruptions). Drones and their autonomous bullets are the pawns, but the players are human decision-makers, constrained by politics and profit. The system runs countless scenarios: a drone swarm cripples a port, triggering a naval response, spiking oil prices, and collapsing a coalition. Another sees a small state’s cheap drones hold off a giant, forcing a negotiated peace.
The output isn’t a single prediction, but a spectrum 75% chance of victory if X holds, 40% if Y defects, 10% if the economy tanks. Commanders could tweak inputs more drones, better AI, a preemptive cyberstrike and watch the probabilities shift. It’s not infallible; black swans like a rogue AI bug or a sudden uprising defy the math. But it’s close enough to turn war into a science, reducing the fog Clausewitz warned of to a manageable haze [1].
The thing that hath been, it is that which shall be; and that which is done is that which shall be done: and there is no new thing under the sun.
~ Ecclesiastes 1:9, KJV
Yet, this raises a haunting question: If we can compute warfare’s endgame, do we lose something essential in the process?
The chaos of flawed, emotional, unpredictable human decision-making has long been the wildcard that defies calculation. Napoleon’s audacity, the Blitz’s resilience, and the guerrilla fighters’ improvisation are not easily reduced to code. Drones and their self-directed progeny promise efficiency, but they also threaten to strip war of its human texture, turning it into a sterile exercise in optimization. And what of accountability? When a bullet chooses its target, who bears the moral weight—the coder, the commander, or the machine itself?
The implications stretch beyond the battlefield. If drones dominate warfare, the barriers to entry collapse. No longer will nations need vast armies or industrial might; a few clever engineers and a swarm of cheap, autonomous systems could level the playing field. We’ve seen glimpses of this in Ukraine, where off-the-shelf drones have humbled tanks and disrupted supply lines. Scale that up, and the future isn’t just drones it’s a proliferation of power, a democratization of destruction. Autonomous bullets could become the ultimate equalizer or the ultimate chaos agent, depending on who wields them.
Fighting for peace is like screwing for virginity.
~ George Carlin
A Moment of Clarity
i wonder: are we ready to surrender the reins? The dream of computing warfare’s outcome is seductive and humans are carnal creatures we lust for other humans and things, thus it promises to minimize loss, to replace guesswork with certainty, but it also risks turning us into spectators of our own fate, watching as machines play out scenarios we’ve set in motion (that which we lust after).
The end state of drones may indeed be a battlefield of self-directed systems, but the end state of humanity in that equation remains unclear. Perhaps the true revolution isn’t in the technology but in how we grapple with a world where war becomes a problem to be solved rather than a story to be lived.
We underestimate drones at our peril. They’re not just tools; they’re harbingers of a paradigm shift. The future is coming, and it’s buzzing overhead—relentless, autonomous, and utterly indifferent to our nostalgia for the wars of old.
Pre-computing warfare might make us too confident. Leaders who trust the model might rush to conflict, assuming the odds are locked. But humans aren’t algorithms; we rebel, err, and surprise. And what of ethics? A simulation that optimizes for victory might greenlight drone strikes on civilians to break morale, justified by a percentage point. The autonomous bullet doesn’t care; it’s our job to decide if the computation is worth the soul it costs.
In this drone-driven future, pre-computing warfare isn’t just possible—it’s already beginning. Ukraine’s drone labs, China’s swarm tests, the Pentagon’s AI budgets—they’re all steps toward a world where conflict is a solvable problem. It has been said that fighting and sex are the two book ends but one in the same. But as we build the machine to predict the fight, we must ask: are we mastering war, or merely handing it a new master for something else entirely?
Music To Blog By: Project-X “Closing Down The Systems. Actually, I wouldn’t listen to this if i were you, unless you want to have nightmares. Fearless (MZ412 Remix) does sound like computational warfare.
Until then,
#iwishyouwater <- recent raw Pipe footage of folks that got the memo.
Ted ℂ. Tanner Jr. (@tctjr) / X
References:
[1] “On War” by Carl von Clausewitz. He called it “The Fog of War”: Clausewitz stressed the importance of understanding the unpredictable nature of war, noting that the “fog of war” (i.e., incomplete, dubious, and often erroneous information and great fear, doubt, and excitement) can lead to rapid decisions by alert commanders.
[2] Thanks to Jay Sales for being the catalyst for this blog. If you do not know who he is look him up here. Jay Sales. One of the best engineering executives and dear friend.












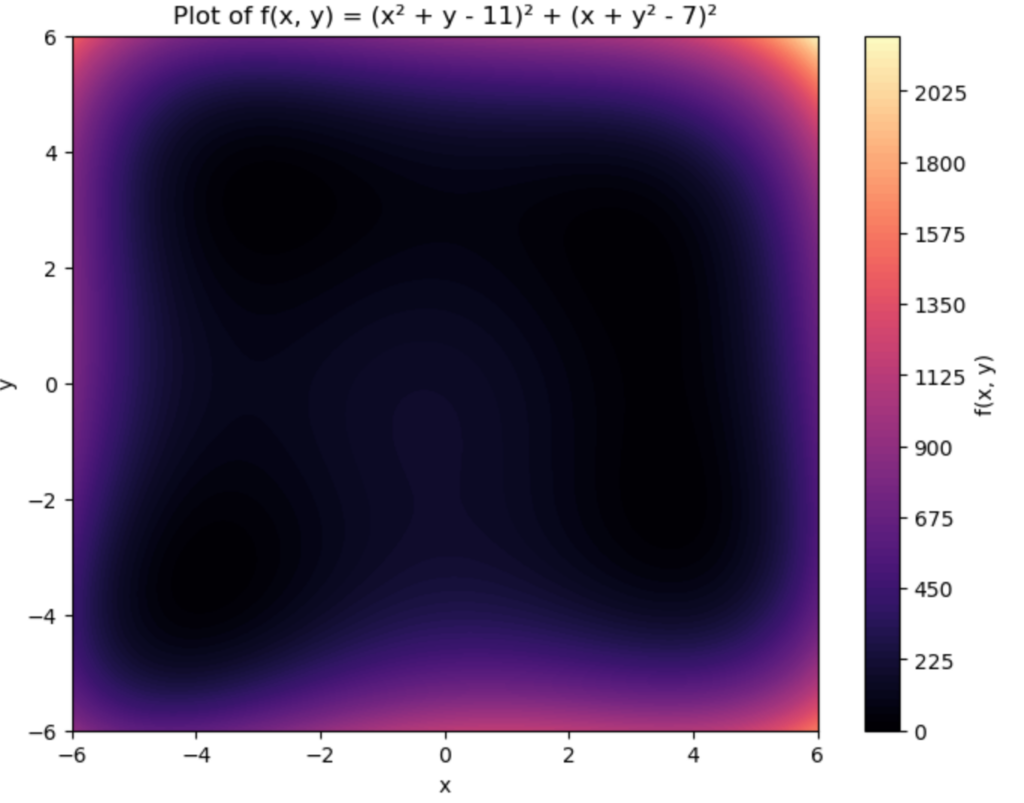
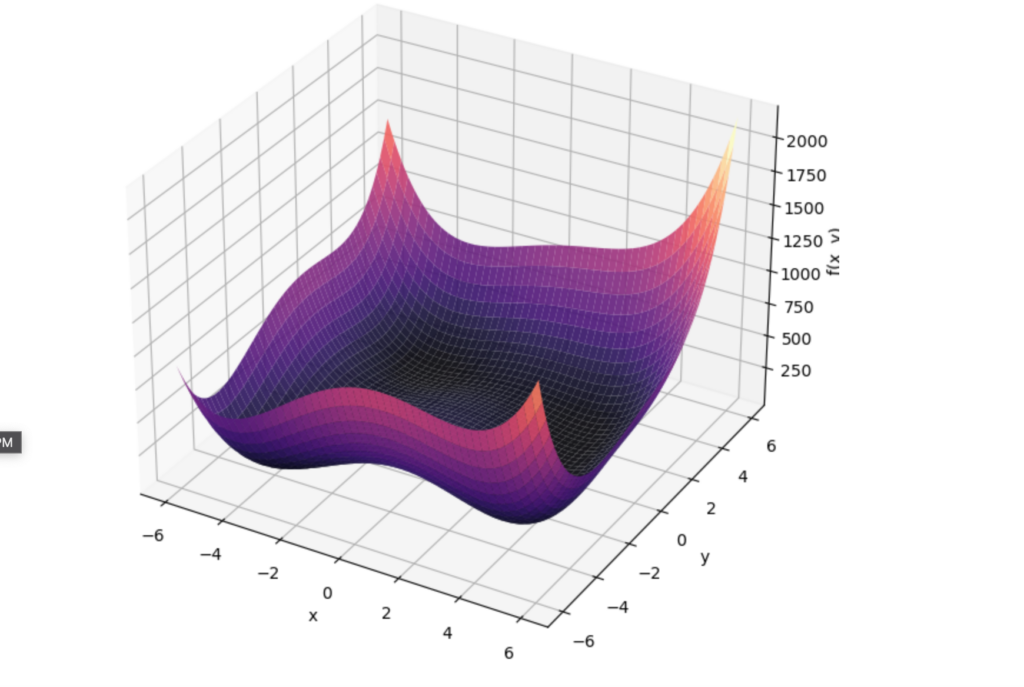
![\[f(x, y) = (x^2 + y - 11)^2 + (x + y^2 - 7)^2\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-23ec65f33d158fdb3b13461e54d04f1a_l3.png "Rendered by QuickLaTeX.com")
 :
:
 and
and  and
and  .
.

 and a transition matrix
and a transition matrix  , where each element
, where each element  represents the probability of transitioning from state
represents the probability of transitioning from state  to state
to state  .
.
 , a point in the state space. This point can be chosen randomly or based on prior knowledge.
, a point in the state space. This point can be chosen randomly or based on prior knowledge. , propose a new state
, propose a new state  using a proposal distribution
using a proposal distribution  , which suggests a candidate for the next state. This proposal distribution can be symmetric (e.g., a normal distribution centered at
, which suggests a candidate for the next state. This proposal distribution can be symmetric (e.g., a normal distribution centered at  for moving from the current state
for moving from the current state ![\[\alpha = \min \left(1, \frac{\pi(x^) q(x_t | x^)}{\pi(x_t) q(x^* | x_t)} \right)\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-d0021c453163124b132e82a38dbf20bb_l3.png "Rendered by QuickLaTeX.com")
 , the formula simplifies to:
, the formula simplifies to:![\[\alpha = \min \left(1, \frac{\pi(x^*)}{\pi(x_t)} \right)\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-52d53f2c5d02dc0c354ef060a927b5de_l3.png "Rendered by QuickLaTeX.com")
 from a uniform distribution
from a uniform distribution 
 , accept the proposed state
, accept the proposed state  .
. , reject the proposed state and remain at the current state, i.e.,
, reject the proposed state and remain at the current state, i.e.,  .
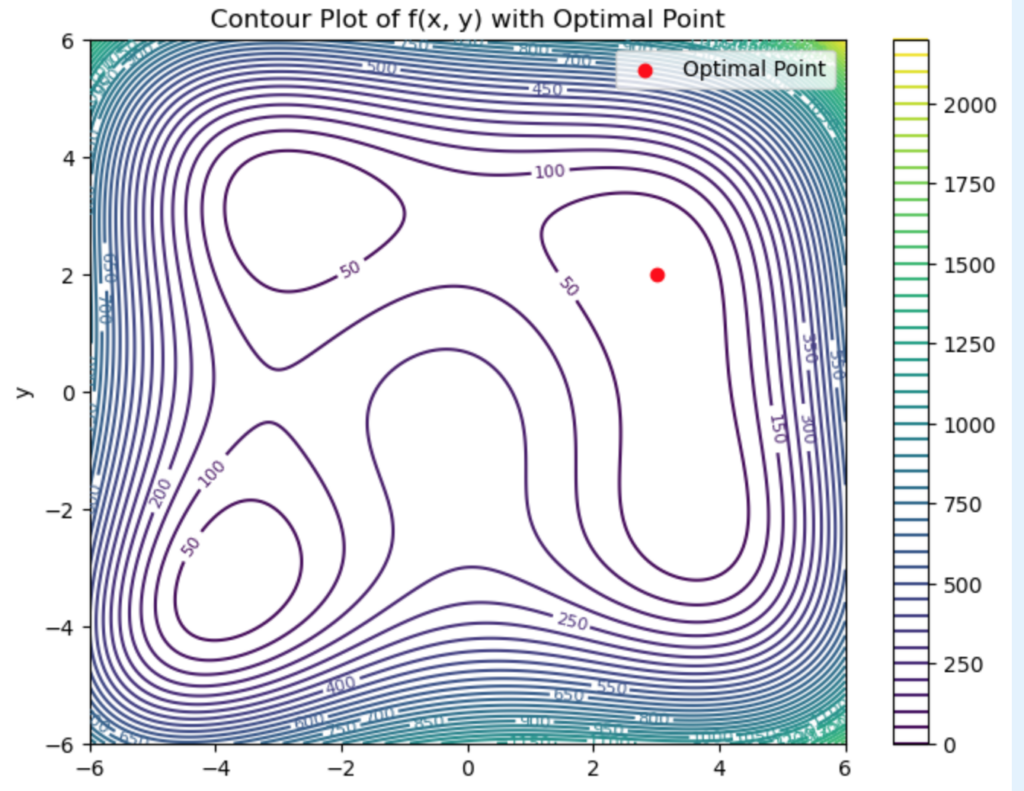
. , which changes slowly over time. We’ll use a simple time-series analytics setup to sample this distribution using the Metropolis Algorithm and plot the results. Note: When the target distribution is Gaussian (or close to Gaussian), the algorithm can converge more quickly to the true distribution because of the symmetric smooth nature of the normal distribution.
, which changes slowly over time. We’ll use a simple time-series analytics setup to sample this distribution using the Metropolis Algorithm and plot the results. Note: When the target distribution is Gaussian (or close to Gaussian), the algorithm can converge more quickly to the true distribution because of the symmetric smooth nature of the normal distribution. ', color='red', linewidth=2)
plt.title("Metropolis Algorithm Sampling with Time-Varying Gaussian Distribution")
plt.xlabel("Time")
plt.ylabel("Sample Value")
plt.legend()
plt.grid(True)
plt.show()
', color='red', linewidth=2)
plt.title("Metropolis Algorithm Sampling with Time-Varying Gaussian Distribution")
plt.xlabel("Time")
plt.ylabel("Sample Value")
plt.legend()
plt.grid(True)
plt.show()
 defines a time-varying mean for the distribution. In this example, it follows a sinusoidal pattern.
defines a time-varying mean for the distribution. In this example, it follows a sinusoidal pattern.


![\[(E_i^*,E_j^*)\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-4b7772a3028c53b1f55a34079971f64d_l3.png "Rendered by QuickLaTeX.com")
![\[H=-1/N \sum_{i=1}^{N} P_i\,log_2\,P_i\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-5a3422c3ff70f85af819c83d0790d495_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\partial u}{\partial t} &= D_u \nabla^2 u + f(u, v),\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-99147d396c77a8652cc77ac0cab65ffe_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\partial v}{\partial t} &= D_v \nabla^2 v + g(u, v),\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-a0acfd5f636e96e9c05ed136c210b906_l3.png "Rendered by QuickLaTeX.com")

![\[\begin{itemize}\item $u$ and $v$ are concentrations of two chemical substances (morphogens),\item $D_u$ and $D_v$ are diffusion coefficients for $u$ and $v$,\item $\nabla^2$ is the Laplacian operator, representing spatial diffusion,\item $f(u, v)$ and $g(u, v)$ are reaction terms representing the interaction between $u$ and $v$.\end{itemize}\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-3c0fe86ddd76baee1115898f2a4cd86e_l3.png "Rendered by QuickLaTeX.com")

 𝕋𝕖𝕕 ℂ. 𝕋𝕒𝕟𝕟𝕖𝕣 𝕁𝕣. (@tctjr) / X
𝕋𝕖𝕕 ℂ. 𝕋𝕒𝕟𝕟𝕖𝕣 𝕁𝕣. (@tctjr) / X

 be
be  -dimensional vectors taking real numbers as their entries. For example:
-dimensional vectors taking real numbers as their entries. For example:
 are the indices respectively. In this case [3].
are the indices respectively. In this case [3]. -by-
-by- . The transpose of a matrix is denoted as
. The transpose of a matrix is denoted as  . A matrix
. A matrix  can be viewed according to its columns and its rows:
can be viewed according to its columns and its rows:
 are the row and column indices.
are the row and column indices.  is usually denoted as a scalar:
is usually denoted as a scalar:
 yields:
yields:


 and
and  equals the length of
equals the length of