

OpenAI’s idea of The Valley – Its Been A Minute
Embrace the unknown and embrace change. That’s where true breakthroughs happen.
~Jensen Huang
First i trust everyone is safe. Second i usually do not write about discrete events or “work” related items but this is an exception. March 17-21, 2025 i and some others attended NVIDIA GTC2025. It warranted a long writeup. Be Forewarned: tl;dr. Read on Dear Reader. Hope you enjoy this one as it is a sea change in computing and a tectonic ocean shift in technology.
NVIDIA GTC 2025: AI’s Raw Hot Buttered Future
March 17-21, 2025, San Jose became geek central for NVIDIA’s GTC—aka the “Super Bowl of AI.” Hybrid setup, in-person or virtual, didn’t matter; thousands of devs, researchers, and suits swarmed to see what’s cooking in AI, GPUs, and robotics. Jensen Huang dropped bombs in his keynote, 1,000+ sessions drilled into the guts of it, and big players flexed their wares. Here’s the raw dog buttered scoop—and why you should care if you sling code or ship product.
The time has come,’ the Walrus said,
To talk of many things:
Of shoes — and ships — and sealing-wax —
Of cabbages — and kings —
And why the sea is boiling hot —
And whether pigs have wings.’
~ The Walrus and The Carpenter

All The Libraries
Jensen’s Keynote: AI’s Next Gear, No Hype
March 18, 2025 SAP Center and the MCenery Civic Center, over 28,000 geeks packed in both halls and out in the streets . Jensen Huang, NVIDIA’s leather-jacketed maestro, hit the stage and didn’t waste breath. 2.5 hours no notes and started with the top of the stack with all the libraries NVIDIA has “CUDA-ized” and went all the way down to the photonic ethernet cables. No corporate fluff, just tech meat for the developer carnivore. His pitch: AI’s not just chatbots anymore; it’s “agentic,” thinking and moving in the real world forward at the speed of thought. Backed up with specifications, cycles, cost and even calling out library function calls.
Here’s what he unleashed:
- Blackwell Ultra (B300): Mid-cycle beast, 288GB memory, out H2 2025. Training LLMs that’d choke lesser rigs—AMD’s sniffing, but NVIDIA’s still king.
- Rubin + Vera Rubin: GPU + CPU superchip combo, late 2026. Named for the galaxy guru, it’s Grace Blackwell’s heir. Full-stack domination vibes.
- Physical AI & GR00T N1: Robots that do real things. GR00T’s a humanoid platform tying training together, synced with Omniverse and Cosmos for digital twin sims. Robotics just got real even surreal.
- NVIDIA Dynamo: “AI Factory OS.” Data centers as reasoning engines, not just compute mules. Deploy AI without the usual ops nightmare. <This> will change it all.
- Quantum Day: IonQ, D-Wave, Rigetti execs talking quantum. It’s distant, but NVIDIA’s planting CUDA flags for the long game.
Jensen’s big claim: AI needs 100 more computing than we thought. That’s not a flex it’s a warning. NVIDIA’s rigging the pipes to pump it.
He said thank you to the developer more than 5 times, mentioned open source at least 4 times and said ecosystem at least 5 times. It was possibly the best keynote i have ever seen and i have been to and seen some of the best. Zuckerburg was right – if you do not have a technical CEO and a technical board, you are not a technical company at heart.

Jensen with Disney Friend
What It Means: Unfiltered and Untrained Takeaways
As i said GTC 2025 wasn’t a bloviated sales conference taking over a city; it was the tech roadmap, raw and real:
- AI’s Next Frontier: The shift to agentic AI and physical AI (e.g., robotics) suggests that AI is moving beyond chatbots and image generation into real-world problem-solving. NVIDIA’s hardware and software innovations—like Blackwell Ultra and Dynamo—position it as the enabler of this transition.
- Compute Power Race: Huang’s claim of a 100x compute demand surge underscores the urgency for scalable, energy-efficient solutions. NVIDIA’s full-stack approach (hardware, software, networking) gives it an edge, though competition from AMD and custom chipmakers looms.
- Robotics Revolution: With GR00T and related platforms, NVIDIA is betting big on robotics as a 50 trillion dollar opportunity. This could transform industries like manufacturing and healthcare, making 2025 a pivotal year for robotic adoption.
- Ecosystem Dominance: NVIDIA’s partnerships with tech giants and startups alike reinforce its role as the linchpin of the AI ecosystem. Its 82% GPU market share may face pressure, but its software (e.g., CUDA, NIM) and services (e.g., DGX Cloud) create a formidable moat.
- Long-Term Vision: The focus on quantum computing and the next-next-gen architectures (like Feynman, slated for 2028) shows NVIDIA isn’t resting on its laurels. It’s preparing for a future where AI and quantum tech converge.
Sessions: Ship Code, Not Slides
Over 1,000 sessions at the McEnery Convention Center. No hand-holding pure tech fuel for devs and decision-makers. Standouts:
- Generative AI & MLOps: Scaling LLMs without losing your mind (or someone else’s). NVIDIA’s inference runtime and open models cut the fat—production-ready, not science-fair thoughting.
- Robotics: Isaac and Cosmos hands-on. Simulate, deploy, done. Manufacturing and healthcare devs, this is your cue.
- Data Centers: DGX Station’s 20 petaflops in a box. Next-gen networking talks had the ops crowd drooling.
- Graphics: RTX for 2D/3D and AR/VR. Filmmakers and game devs got a speed boost—less render hell.
- Quantum: Day-long deep dive. CUDA’s quantum bridge is speculative, but the math’s stacking up.
- Digital Twins and Simulation: Omniverse™ provides advanced simulation capabilities for adding true-to-reality physics to scene compositions. Build on models from basic rigid-body simulation to destruction, fluid-dynamics-based fire simulation, and physics-based scene authoring.

Near Real-Time Digital Twin Rendering Of A Ship
The DGX Spark Computer
i personally thought this deserved its own call-out. The announcement of the DGX Spark Computer. It is a compact AI supercomputer. Let us unpack its specs and capabilities for training large language models (LLMs). This little beast is designed to bring serious AI firepower to your desk, so here’s the rundown based on what NVIDIA has shared at the conference.
The DGX Spark is powered by the NVIDIA GB10 Grace Blackwell Superchip, a tightly integrated combo of CPU and GPU muscle. Here’s what it’s packing:
- GPU: Blackwell GPU with 5th-generation Tensor Cores, supporting FP4 precision (4-bit floating-point). NVIDIA claims it delivers up to 1,000 AI TOPS (trillions of operations per second) at FP4—insane compute for a desktop box.
- CPU: 20 Armv9 cores (10 Cortex-X925 + 10 Cortex-A725), connected to the GPU via NVIDIA’s NVLink-C2C interconnect. This gives you 5x the bandwidth of PCIe Gen 5, keeping data flowing fast between CPU and GPU.
- Memory: 128 GB of unified LPDDR5x with a 256-bit bus, clocking in at 273 GB/s bandwidth. This unified memory pool is shared between CPU and GPU, critical for handling big AI workloads without choking on data transfers.
- Storage: Options for 1 TB or 4 TB NVMe SSD—plenty of room for datasets, models, and checkpoints.
- Networking: NVIDIA ConnectX-7 with 200 Gb/s RDMA (scalable to 400 Gb/s when pairing two units), plus Wi-Fi 7 and 10GbE for wired connections. You can cluster two Sparks to double the power.
- I/O: Four USB4 ports (40 Gbps), HDMI 2.1a, Bluetooth 5.3—modern connectivity for hooking up peripherals or displays.
- OS: Runs NVIDIA DGX OS, a custom Ubuntu Linux build loaded with NVIDIA’s AI software stack (CUDA, NIM microservices, frameworks, and pre-trained models).
- Power: Sips just 170W from a standard wall socket—efficient for its punch.
- Size: Tiny at 150 mm x 150 mm x 50.5 mm (about 1.1 liters) and 1.2 kg—it’s palm-sized but packs a wallop.

The DGX Spark Computer
This thing’s a sleek, power-efficient monster styled like a mini NVIDIA DGX-1, aimed at developers, researchers, and data scientists who want data-center-grade AI on their desks – in gold metal flake!
Now, the big question: how beefy an LLM can the DGX Spark train? NVIDIA’s marketing pegs it at up to 200 billion parameters for local prototyping, fine-tuning, and inference on a single unit. Pair two Sparks via ConnectX-7, and you can push that to 405 billion parameters. But let’s break this down practically—training capacity depends on what you’re doing (training from scratch vs. fine-tuning) and how you manage memory.
- Fine-Tuning: NVIDIA highlights fine-tuning models up to 70 billion parameters as a sweet spot for a single Spark. With 128 GB of unified memory, you’re looking at enough space to load a 70B model in FP16 (16-bit floating-point), which takes about 140 GB uncompressed. Techniques like quantization (e.g., 8-bit or 4-bit) or offloading to SSD can stretch this further, but 70B is the comfy limit for active fine-tuning without heroic optimization.
- Training from Scratch: Full training (not just fine-tuning) is trickier. A 200B-parameter model in FP16 needs around 400 GB of memory just for weights, ignoring gradients and optimizer states, which can triple that to 1.2 TB. The Spark’s 128 GB can’t handle that alone without heavy sharding or clustering. NVIDIA’s 200B claim likely assumes inference or light fine-tuning with aggressive quantization (e.g., FP4 via Tensor Cores), not full training. For two units (256 GB total), you might train a 200B model with extreme optimization—think model parallelism and offloading—but it’s not practical for most users.
- Real-World Limit: For full training on one Spark, you’re realistically capped at 20-30 billion parameters in FP16 with standard methods (weights + gradients + Adam optimizer fit in 128 GB). Push to 70B with quantization or two-unit clustering. Beyond that, 200B+ is more about inference or fine-tuning pre-trained models, not training from zero.
Not bad for 4000.00. Think of all the things you could do… All of the companies you could build… Now onto the sessions.
Speakings and Sessions
There were 2,000+ speakers, some Nobel-tier, delivered. Straight no chaser – code, tools, and war stories. Hardcore programming sessions on CUDA, NVIDIA’s parallel computing platform, and tools like Dynamo (the new AI Factory OS). Think line-by-line breakdowns of optimizing AI models or squeezing performance from Blackwell Ultra GPUs. Once again, slideware jockeys need not apply.
The speaker list was a who’s-who of brainpower and hustle. Nobel laureates like Frances Arnold brought scientific heft—imagine her linking GPU-accelerated protein folding to drug discovery. Meanwhile, Yann LeCun and Noam Brown (OpenAI) tackled AI’s bleeding edge, like agentic reasoning or game theory hacks. Then you had practitioners Joe Park (Yum! Brands) on AI for fast food RJ Scaringe (Rivian) on autonomous driving, grounding it in real-world stakes.
Literally, a who-who of the AI developer world baring souls (if they have one) and scars from the war stories, and they do have them.
There was one talk in particular that was probably one of the best discussions i have seen in the past decade. SoFar Ocean Technologies is partnering with MITRE and NVIDIA to power the future of ocean AI!
MITRE announced a joint effort to build an AI-powered ocean digital twin fueled by real-time data from the global Spotter network. Researchers, government, and industry will use the digital twin to simulate and better understand the marine environments in which they operate.
As AI supercharges weather prediction, even the most advanced models will need more ocean data to be effective. Sofar provides these essential observations at scale. To power the digital twin, SoFar will deliver data from their global network of real-time ocean sensors and collaborate with MITRE to rapidly expand the adoption of the Bristlemouth open connectivity standard. Live data will feed into the NVIDIA Omniverse and open up new pathways for AI-powered ocean understanding.
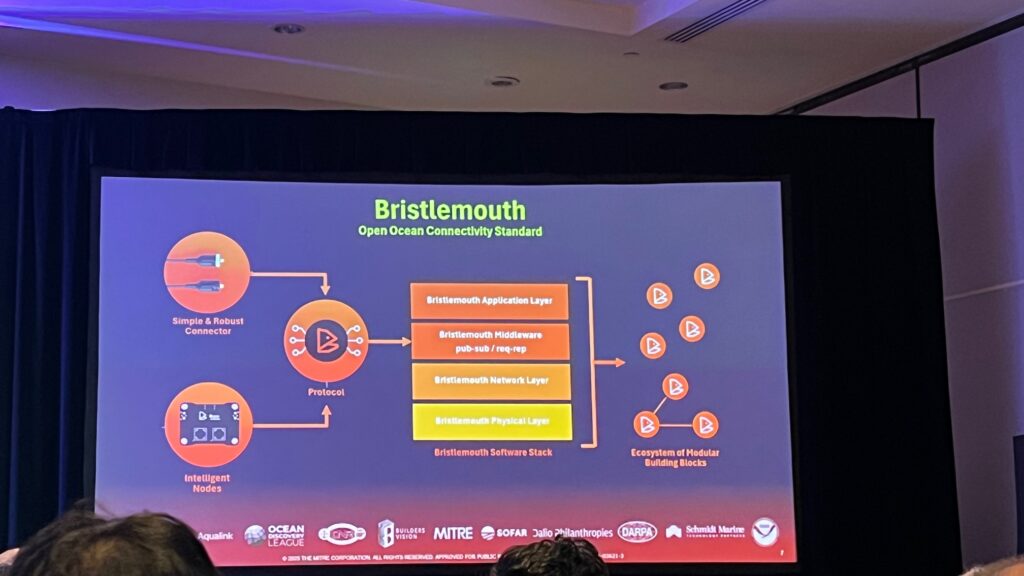
BristleMouth Open Source Orchestration UxV Platform
The systems of systems and ecosystem reach are spectacular. The effort is monumental, and only through software can this scale be achievable. Of primary interest to this ecosystem effort they have partnered with Ocean Exploration Trust and the Nautilus Exploration Program to seek out new discoveries in geology, biology, and archaeology while conducting scientific exploration of the seafloor. The expeditions launch aboard Exploration Vessel Nautilus — a 68-meter research ship equipped with live-streaming underwater vehicles for scientists, students, and the public to explore the deep sea from anywhere in the world. We embed educators and interns in our expeditions who share their hands-on experiences via ship-to-shore connections with the next generation. Even while they are not at sea, explorers can dive into Nautilus Live to learn more about our expeditions, find educational resources, and marvel at new encounters.
“The most powerful technologies are the ones that empower others.”
~Jensen Huang

The Nautilus Live Mapping Software
At the end of the talk, I asked a question on the implementation of AI Orchestration for sensors underwater as well as personally thanked Dr Robert Ballard, who was in the audience, for his amazing work. Best known for his 1985 discovery of the RMS Titanic, Dr. Robert Ballard has succeeded in tracking down numerous other significant shipwrecks, including the German battleship Bismarck, the lost fleet of Guadalcanal, the U.S. aircraft carrier Yorktown (sunk in the World War II Battle of Midway), and John F. Kennedy’s boat, PT-109.
Again Just amazing. Check out the work here: SoFar Ocean.
What Was What: Big Dogs and Upstarts
The Exhibit hall was a technology zoo and smorgasbord —400+ OGs and players showing NVIDIA’s reach. (An Introvert’s Worst Nightmare.) Who showed up:
- Tech Giants: Adobe, Amazon, Microsoft, Google, Oracle. AWS and Azure lean hard on NVIDIA GPUs—cloud AI’s backbone.
- AI Hotshots: OpenAI and DeepSeek. ChatGPT’s parents still ride NVIDIA silicon; efficiency debates be damned.
- Robots & Cars: Tesla hinting at autonomy juice, Delta poking at aviation AI. NVIDIA’s tentacles stretch wide.
- Quantum Crew: Alice & Bob, D-Wave, IonQ, Rigetti. Quantum’s sci-fi, but they’re here.
- Hardware: Dell, Supermicro, Cisco with GPU-stuffed rigs. Ecosystem’s locked in.
- AI Platforms: Edge Impulse, Clear ML, Haystack – you need training and ML deployment they had it.
Inception Program: Fueling the Next Wave
Now, the Inception program—NVIDIA’s startup accelerator—is the unsung hero of GTC. With over 22,000 members worldwide, it’s a breeding ground for AI innovation, and GTC 2025 was their stage. Nearly 250 Inception startups showed up, from healthcare disruptors to robotics trailblazers like Stelia (shoutout to their “petabit-scale data mobility” talk). These aren’t pie-in-the-sky outfits—100+ had speaking slots, and their demos at the Inception Pavilion were hands-on proof of GPU-powered breakthroughs.
The program’s a sweet deal: free to join, no equity grab, just pure support—100K in DGX Cloud credits, Deep Learning Institute training, VC intros via the VC Alliance. They even had a talk on REVERSE VC pitches. What the VCs in Silicon Valley are looking for at the moment, and they were funding companies at the conference! It’s NVIDIA saying, “We’ll juice your tech, you change the game.” At GTC, you saw the payoff—startups like DeepSeek and Baseten flexing optimized models or enterprise tools, all built on NVIDIA’s stack. Critics might say it locks startups into NVIDIA’s ecosystem, but with nearly 300K in credits and discounts on tap, it’s hard to argue against the boost. The war stories from these founders—like scaling AI infra without frying a data center—were gold for any dev in the trenches.
GTC 2025 and Inception are two sides of the same coin. GTC’s the megaphone—blasting NVIDIA’s vision (and hardware) to the world—while Inception’s the incubator, quietly powering the startups that’ll flesh out that vision. Huang’s keynote hyped a token-driven AI economy, and Inception’s crew is already living it, churning out reasoning models and robotics on NVIDIA’s gear. It’s a symbiotic flex: GTC shows the “what,” Inception delivers the “how.”
We’re here to put a dent in the universe. Otherwise, why else even be here?
~ Steve Jobs

Micheal Dell and Your Humble Narrator at the Dell Booth
I did want to call out one announcement that I think has been a long time in the works in the industry, and I have been a very strong evangelist for, and that is a distributed inference OS.
Dynamo: The AI Factory OS That’s Too Cool to Gatekeep
NVIDIA unleashed Dynamo—think of it as the operating system for tomorrow’s AI factories. Huang’s pitch? Data centers aren’t just server farms anymore; they’re churning out intelligence like Willy Wonka’s chocolate factory but with fewer Oompa Loompas (queue the imagination song). Dynamo’s got a slick trick: it’s built from the ground up to manage the insane compute loads of modern AI, whether you’re reasoning, inferring, or just flexing your GPU muscle. And here’s the kicker—NVIDIA’s tossing the core stack into the open-source wild via GitHub. Yep, you heard that right: free for non-commercial use under an Apache 2.0 license. It’s like they’re saying, “Go build your own AI empire—just don’t sue us!” For the enterprise crowd, there’s a beefier paid version with extra bells and whistles (of course). Open-source plus premium? Whoever heard of such a thing! That’s a play straight out of the Silicon Valley handbook.
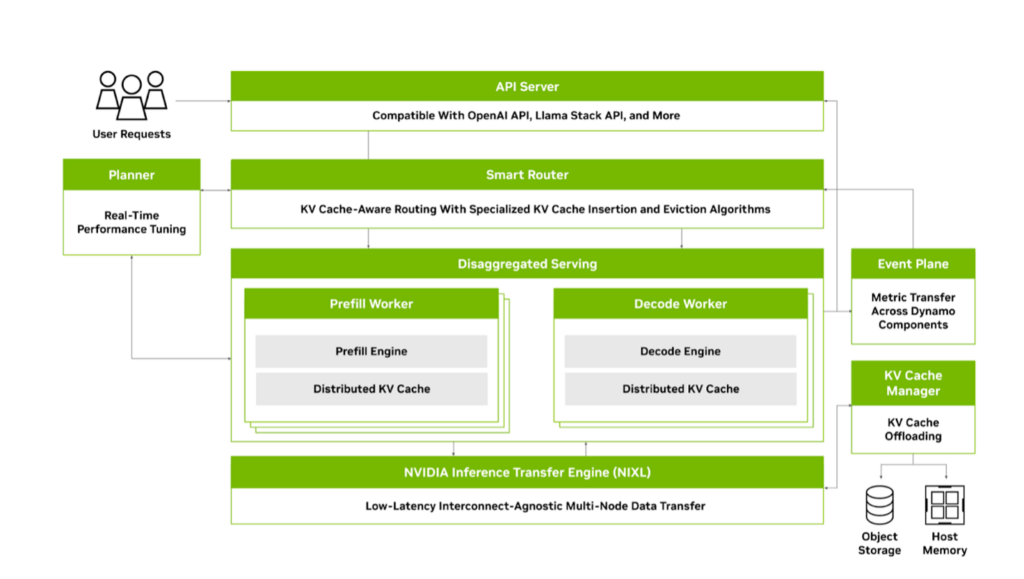
Dynamo High-Level Architecture
Dynamo is high-throughput low-latency inference framework designed for serving generative AI and reasoning models in multi-node distributed environments. Dynamo is designed to be inference engine agnostic (supports TRT-LLM, vLLM, SGLang or others) and captures LLM-specific capabilities such as
- Disaggregated prefill & decode inference – Maximizes GPU throughput and facilitates trade off between throughput and latency.
- Dynamic GPU scheduling – Optimizes performance based on fluctuating demand
- LLM-aware request routing – Eliminates unnecessary KV cache re-computation
- Accelerated data transfer – Reduces inference response time using NIXL.
- KV cache offloading – Leverages multiple memory hierarchies for higher system throughput
Dynamo enables dynamic worker scaling, responding to real-time deployment signals. These signals, captured and communicated through an event plane, empower the Planner to make intelligent, zero-downtime adjustments. For instance, if an increase in requests with long input sequences is detected, the Planner automatically scales up prefill workers to meet the heightened demand.
Beyond efficient event communication, data transfer across multi-node deployments is crucial at scale. To address this, Dynamo utilizes NIXL, a technology designed to expedite transfers through reduced synchronization and intelligent batching. This acceleration is particularly vital for disaggregated serving, ensuring minimal latency when prefill workers pass KV cache data to decode workers.
Dynamo prioritizes seamless integration. Its modular design allows it to work harmoniously with your existing infrastructure and preferred open-source components. To achieve optimal performance and extensibility, Dynamo leverages the strengths of both Rust and Python. Critical performance-sensitive modules are built with Rust for speed, memory safety, and robust concurrency. Meanwhile, Python is employed for its flexibility, enabling rapid prototyping and effortless customization.
Oh yeah, and for all the naysayers over the years, it uses Nats.io as the messaging bus. Here is the Github. Get your fork on, but please contribute back – ya hear?
Tokenized Reasoning Economy
Along with this Dynamo announcement, NVidia has created an economy around tokenized reasoning models, in a monetary sense. This is huge. Let me break this down.
Now, why call this an economy? In a monetary sense, NVIDIA’s creating a system where compute power (delivered via its GPUs) and tokens (the output of reasoning models) act like resources and currency in a marketplace. Here’s how it works:
- Compute as the Factory: NVIDIA’s GPUs—think Blackwell Ultra or Hopper—are the engines that power these reasoning models. The more compute you throw at a problem (more GPUs, more time), the more tokens you can generate, and the smarter the AI’s answers get. It’s like a factory producing goods, but the goods here are tokens representing intelligence.
- Tokens as Currency: In the AI world, tokens aren’t just data—they’re value. Companies running AI services (like chatbots or analytics tools) often charge based on tokens processed—say, (X) dollars per million tokens. NVIDIA’s optimizing this with tools like Dynamo, which boosts token output while cutting costs, essentially making the “token economy” more efficient. More tokens per dollar = more profit for businesses using NVIDIA’s tech. Tokens Per Second will be the new metric.
- Supply and Demand: Demand for reasoning AI is skyrocketing—enterprises, developers, and even robotics firms want smarter systems. NVIDIA supplies the hardware (GPUs) and software (like Dynamo and NIM microservices) to meet that demand. The more efficient their tech, the more customers flock to them, driving sales of GPUs and services like DGX Cloud.
- Revenue Flywheel: Here’s the monetary kicker—NVIDIA’s raking in billions ($39.3B in a single quarter, per GTC 2025 buzz) because every industry needs this tech. They sell GPUs to data centers, cloud providers, and enterprises, who then use them to generate tokens and charge end users. NVIDIA reinvests that cash into better chips and software, keeping the cycle spinning.
NVIDIA’s “tokenized reasoning model economy” is about turning AI intelligence into a scalable, profitable commodity—where tokens are the product, GPUs are the means of production, and the tech industry is the market. The Developers power the Flywheel. Makes the mid-90s look like Bush League sports ball.

Tori MCcaffrey Technical Product Manager Extraordinaire and Your Humble Narrator
All that is really missing is a good artificial intelligence to control the whole process. And that is the trick, isnt it? These types of blue-sky discussions always assume certain advances for a sucessful implmentation. Unfortunately, A.I. is the bottleneck in this case. We’re close with replication and manufacturing processes and we could probably build sufficiently effective ion drives if we had the budget. But we lack a way to provide enought intelligence for the probe to handle all the situations it could face.
~ Eduard Guijpers from the Convention Panel -Designing a Von Nueman Probe

Daily and Lecun – Fireside
Lecun FireSide Chat
Yann LeCun, Turing Award badass and Meta’s AI Chief Scientist brain, sat down for a fireside chat with Bill Daily, Chief Scientist at NVIDIA that cut through the AI hype. No fluffy TED Talk (or me talking) vibes here just hot takes from a guy who’s been torching (get it?) neural net limits since the ‘80s. With Jensen Huang’s “agentic AI” bomb still echoing from the keynote, LeCun brought the dev crowd at the McEnery Civic Center a dose of real talk on where deep learning’s headed.
LeCun didn’t mince words: generative AI’s cool, but it’s a stepping stone. The future’s in systems that reason, not just parrot think less ChatGPT, and more “machines that actually get real work done.” He riffed on NVIDIA’s Blackwell Ultra and GR00T robotics push, nodding to the computing muscle needed for his vision. “You want AI that plans and acts? You’re burning 100x more flops than today,” he said, echoing Jensen’s compute hunger warning. No surprise—he’s been preaching energy-efficient architectures forever.
The discussion further dug into LeCun’s latest obsession: self-supervised learning on steroids. He’s betting it’ll crack real-world perception for robots and autonomous rigs stuff NVIDIA’s Cosmos and Isaac platforms are already juicing. “Supervised learning’s dead-end for scale,” he jabbed. “Data’s the bottleneck, not flops.” There were several nods from the devs in the Civic Center. He also said we would be managing hundreds of agents in the future, vertically trained – horizontally chained so to speak.
No slides once again, just LeCun riffing extempore, per NVIDIA’s style. He dodged the Meta AI roadmap but teased “open science” wins—likely a jab at closed-shop rivals. For devs, it was a call to arms: ditch the hype, build smarter, lean on NVIDIA’s stack. With Quantum Day buzzing next door, he left us with a zinger: “Quantum’s cute, but deep nets will out-think it first.”
GTC’s “Super Bowl of AI” rep held. LeCun proved why he’s still the godfather—unfiltered, technical, and ready to break the next ceiling and pragmatic.

Jay Sales, Engineering Executive Rockstar and Your Humble Narrator
Bottom Line
GTC2025 wasn’t just a conference. GTC 2025 was NVIDIA flipping the table: AI’s industrial now, not academic. Jensen’s vision, the sessions’ grit, and the hall’s buzz screamed one thing—build or get buried. For devs, it’s a CUDA goldmine. For suits, it’s strategy. For the industry, it’s NVIDIA steering the ship—full speed into an AI agentic and robotic future. With San Jose’s dust settling, the code’s just starting to run. Big fish and small fry are all feeding on bright green chips. 5 devs can now do the output of 50. Building stuff so others can build is Our developer mantra. Always has been, always will be – Gabba Gabba Hey One Of Us, One of Us!
Huang’s overarching message was clear: AI is evolving beyond generative models into “agentic AI”—systems that can reason, plan, and act autonomously. This shift demands exponentially more compute power (100x more than previously predicted, he noted), cementing NVIDIA’s role as the backbone of this transformation.
Despite challenges—early Blackwell overheating issues, U.S. export controls, and a 13% stock dip in 2025. Whatevs. NVIDIA’s record-breaking 39.3 billion dollar revenue quarter in February proves its resilience. GTC 2025 reaffirmed that NVIDIA isn’t just riding the AI wave; it’s creating it.
One last thought: a colleague was walking with me around the conference and inquired to me how did this feel and what i thought. Context: i was in The Valley from 1992-2001 and then had a company headquartered out there from 2011-2018. i thought for a moment, looked around, and said, “This feels like 90’s on steroids, which was the heyday of embedded programming and what i think was then the height of some of the most performant code in the valley.” i still remember when at Apple the Nvidia chip was chosen over ATI’s graphics chip. NVIDIA’s stock was something like 2.65 / share. i still remember when at Microsoft the NVIDIA chip was chosen for the XBox. NVIDIA the 33 year old start-up that analyst are talking of the demise. Just like music critics – right? As i drove up and down 101 and 280 i saw all of the new buildings and names – i realized – The Valley Is Back.
until then,
#iwishyouwater <- Mark Healy Solo Outer Reef Memo
Muzak To Blog By: Grotus, stylized as G̈r̈oẗus̈, was an industrial rock band from San Francisco, active from 1989 to 1996. Their unique sound incorporated sampled ethnic instruments, two drummers, and two bassists, and featured angry but humorous lyrics. NIN, Mr Bungle, Faith No More and Jello Biafra championed the band. Not for the faint of heart. Nevertheless great stuff.
Note: Rumor has it the Rivian SUV does in fact, go 0-60 in 2.6 seconds with really nice seats. Also thanks to Karen and Paul for the tea and sympathy steak supper in Palo Alto, Miss ya’ll!

Only In The Valley


 . This notation is known as Dirac’s bra-ket notation. Specifically from a mathematical standpoint and this is why the above uses the label “named” it is represented by a two-dimensional vector space over complex numbers
. This notation is known as Dirac’s bra-ket notation. Specifically from a mathematical standpoint and this is why the above uses the label “named” it is represented by a two-dimensional vector space over complex numbers  . This means that a Qubit takes two complex numbers to fully describe it. Okay so think about that… It takes two numbers to describe the state. Already strange huh? The computational (or standard) basis corresponds to the two levels
. This means that a Qubit takes two complex numbers to fully describe it. Okay so think about that… It takes two numbers to describe the state. Already strange huh? The computational (or standard) basis corresponds to the two levels  and
and  , which corresponds to the following vectors:
, which corresponds to the following vectors: ![\[\begin{split}|0\rangle = \begin{pmatrix}1\\ 0 \end{pmatrix}~~~~|1\rangle=\begin{pmatrix}0\\1\end{pmatrix}\end{split}\]](https://www.tedtanner.org/wp-content/ql-cache/quicklatex.com-f234025776a3b0cd0a4775f203defe43_l3.png "Rendered by QuickLaTeX.com")
 , which can be any superposition
, which can be any superposition  of the basis vectors. The superposition quantities
of the basis vectors. The superposition quantities  and (\beta\) are complex numbers; together they obey
and (\beta\) are complex numbers; together they obey  . Interesting things happen when quantum systems are measured, or observed. Quantum measurement is described by the
. Interesting things happen when quantum systems are measured, or observed. Quantum measurement is described by the  , and the result 1 is obtained with the complementary probability
, and the result 1 is obtained with the complementary probability  . Interestingly, a quantum measurement takes any superposition state of the qubit, and projects it to either the state
. Interestingly, a quantum measurement takes any superposition state of the qubit, and projects it to either the state 


